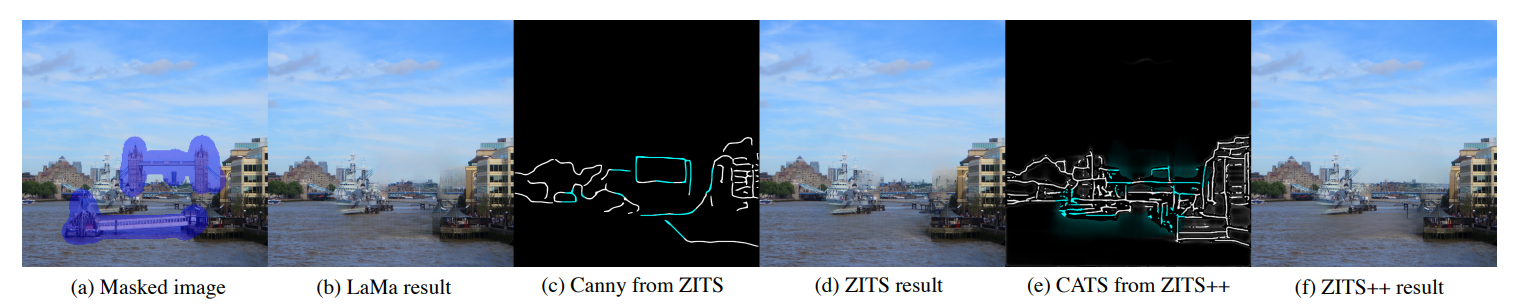
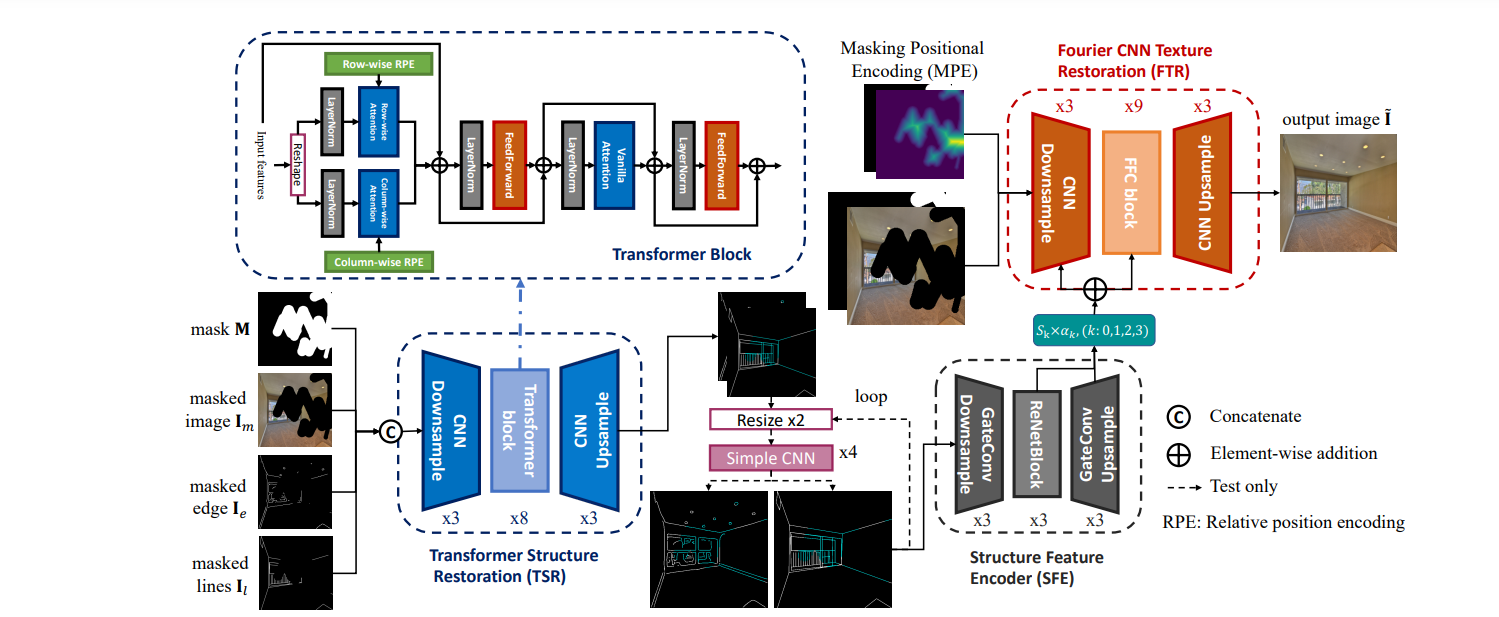
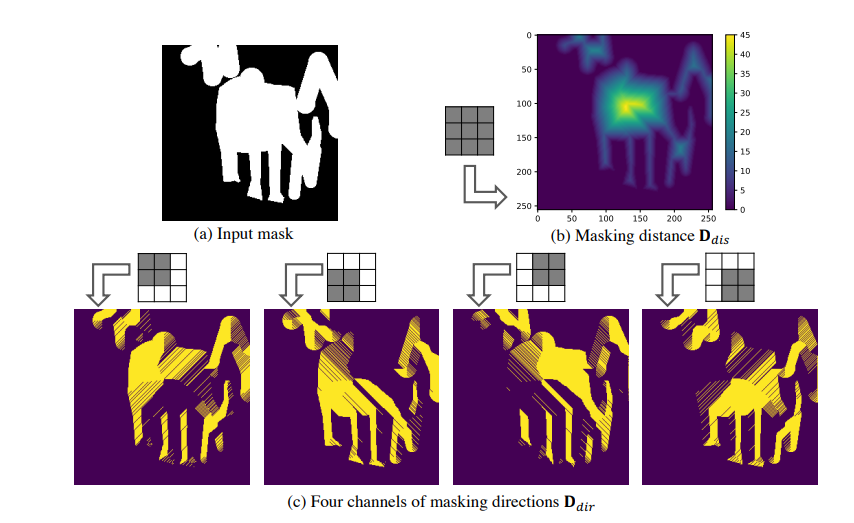
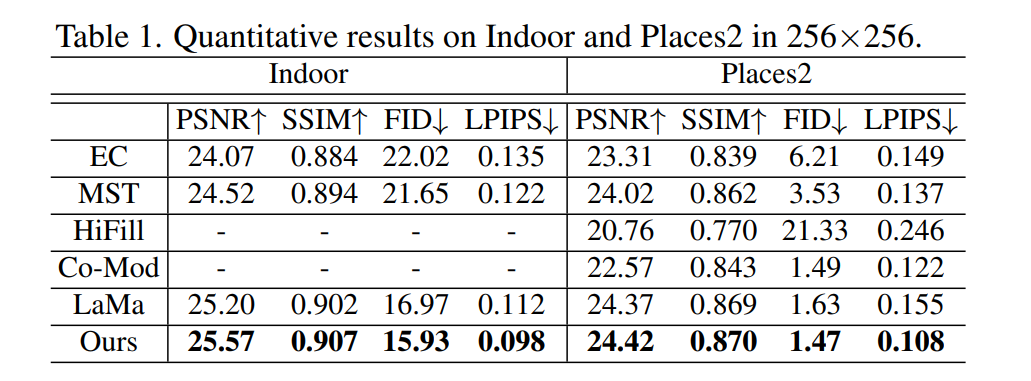
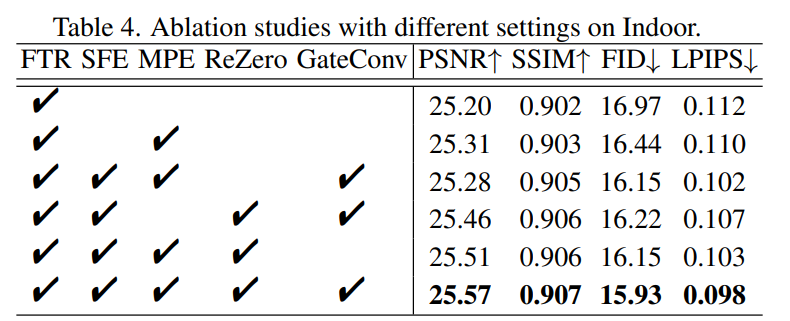
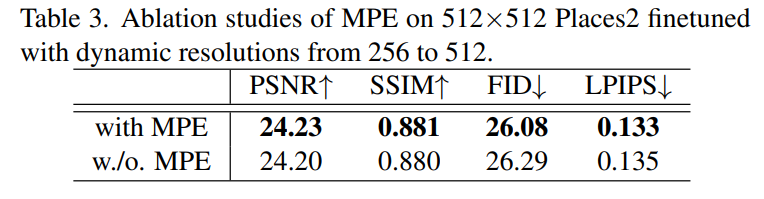
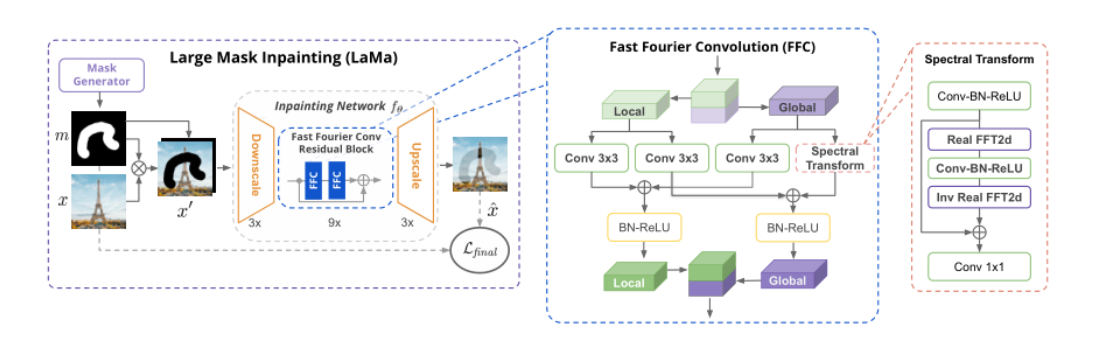
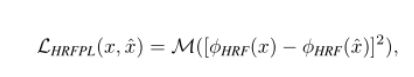Trend | GPT-4 —— The winner takes all
Image and Text Multimodal
We report the development of GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs.
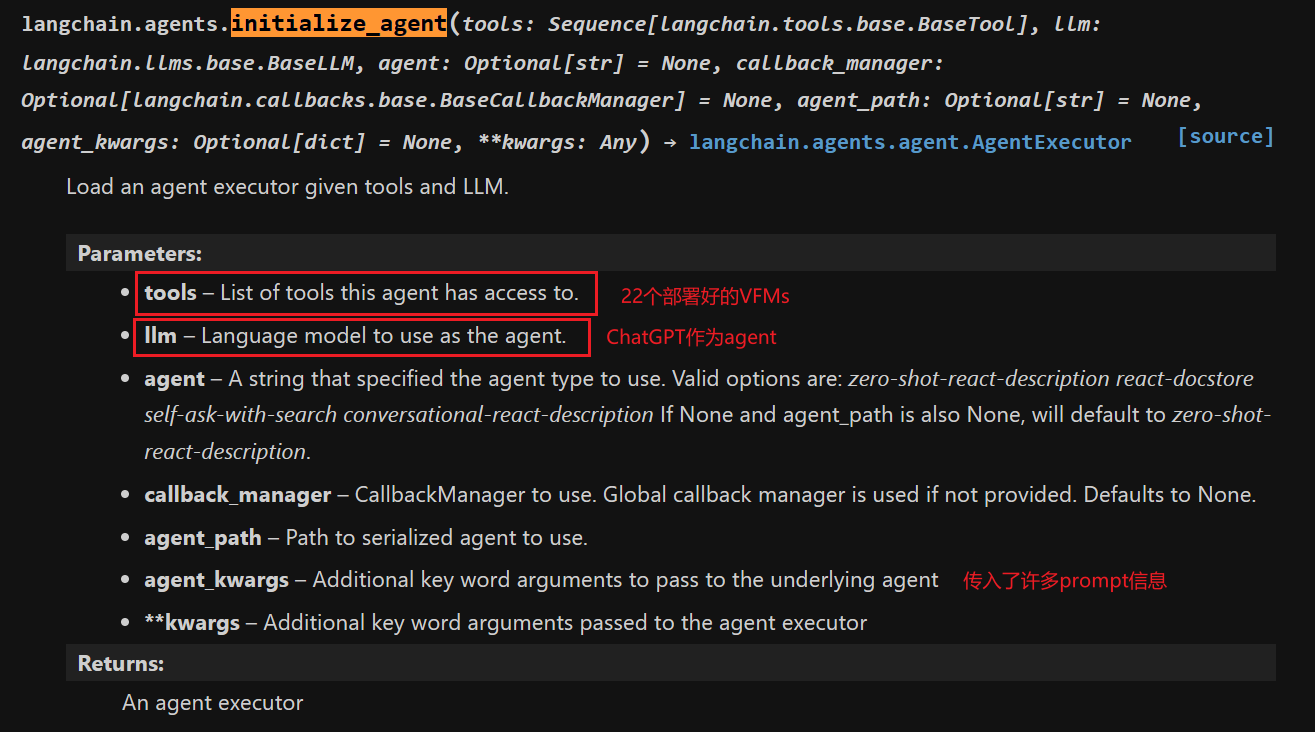
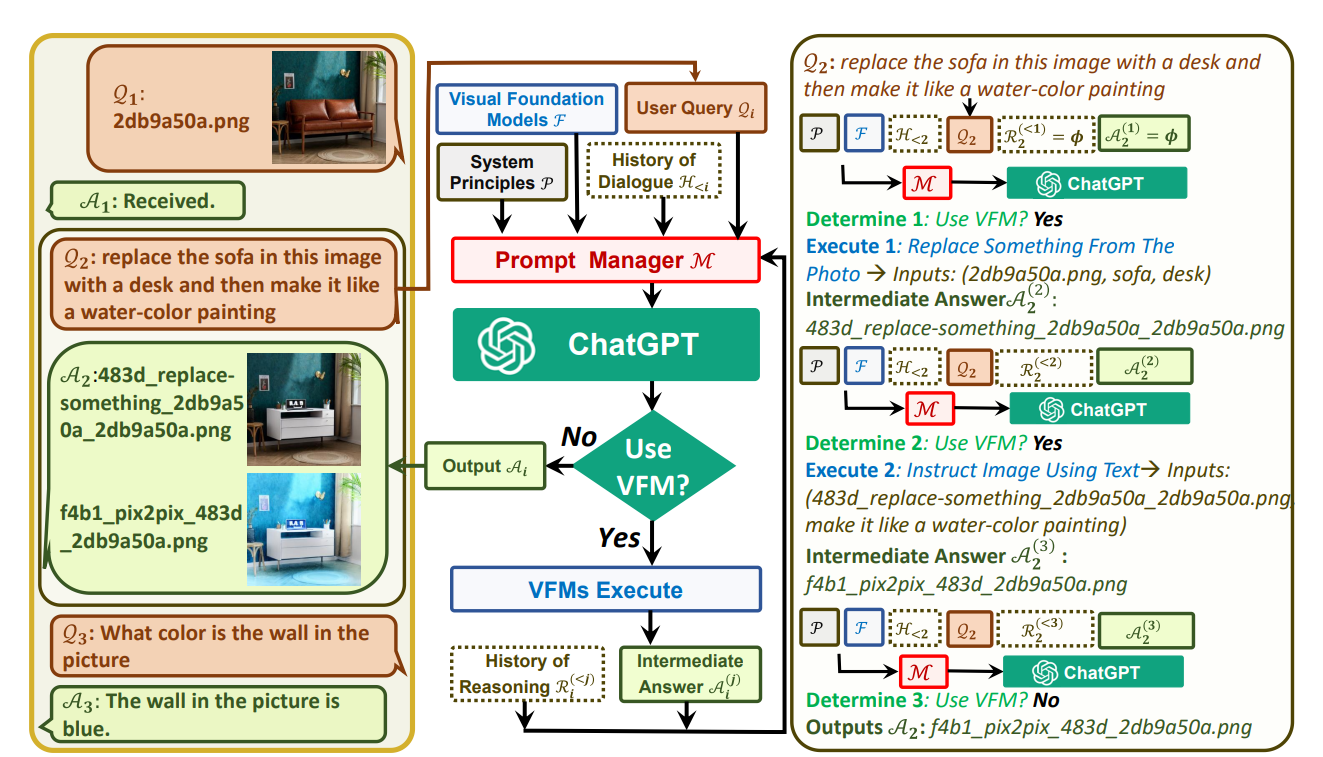
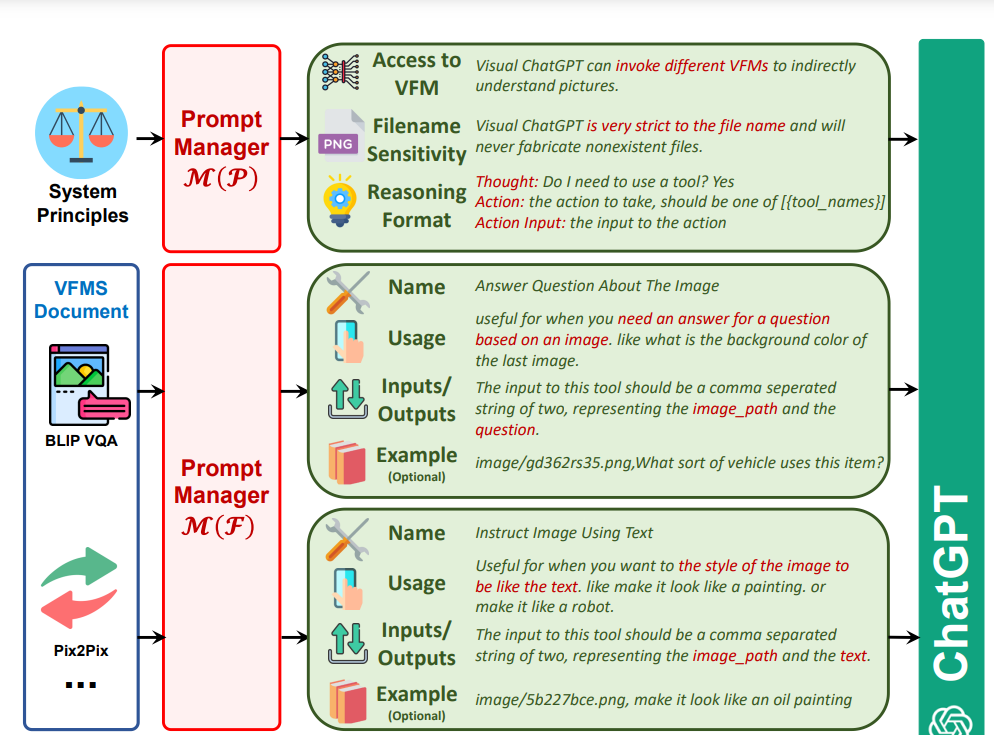
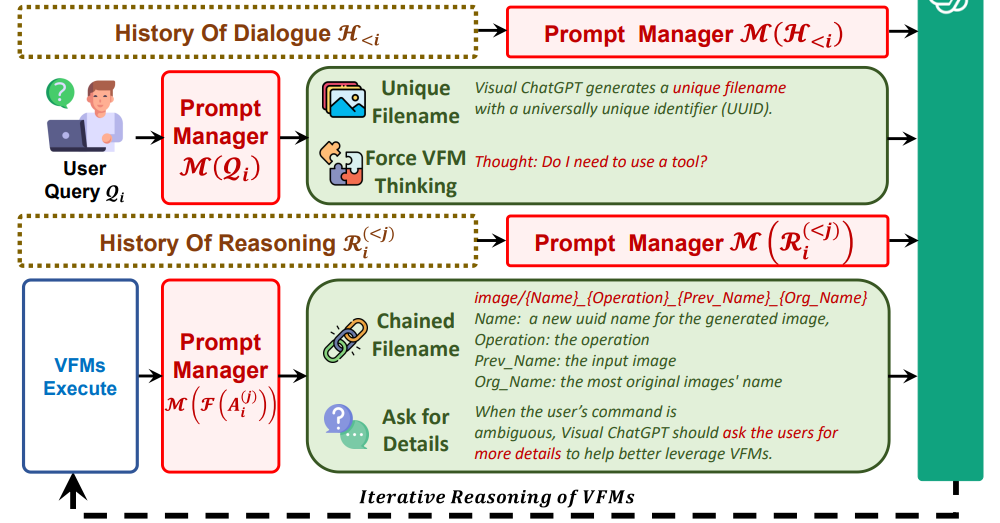
- 模型底层逻辑还是image+text input(融入多模态元素,更唬人一些?),但还是文本outputs(不过听说chatgpt plus版本已经可以有image output了,怀疑是一些命令的组合?就类似于上一篇微软刚提出的Vision Chatgpt的方式一样,将视觉模型作为tool模型,large-scale语言预训练作为agent模型)。
- 支持输入更多的tokens(更个性化,更方便定制了,更task-specific了)
- 加了一些VQA的性能对比。
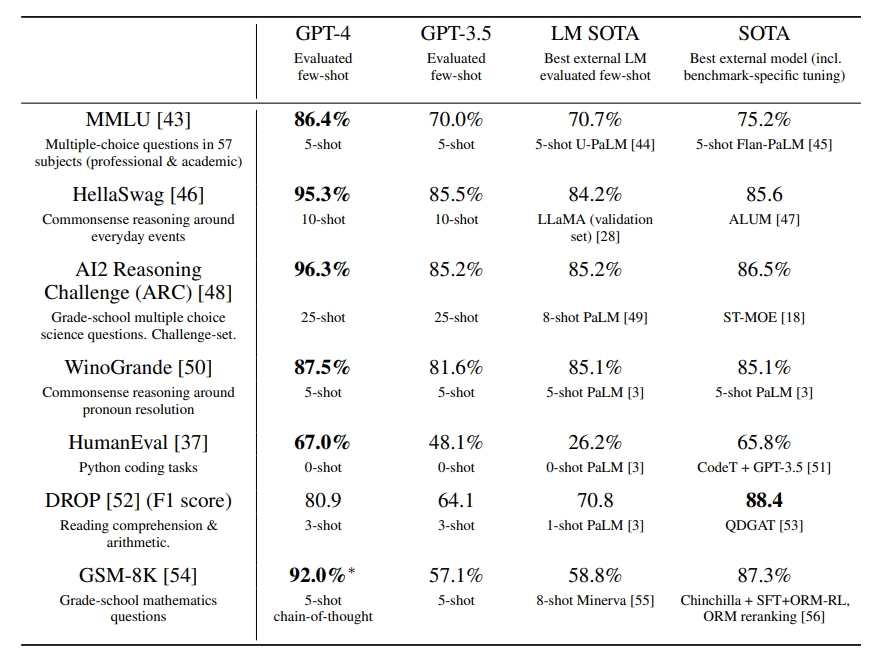
Professional and Academic Benchmarks
While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers.
- professional benchmarks
乱杀应试教育界,秒杀多少普通人。
AI for science提上日程吧,早日研究,然后自我替代(开玩笑,不过很期待这一天)。
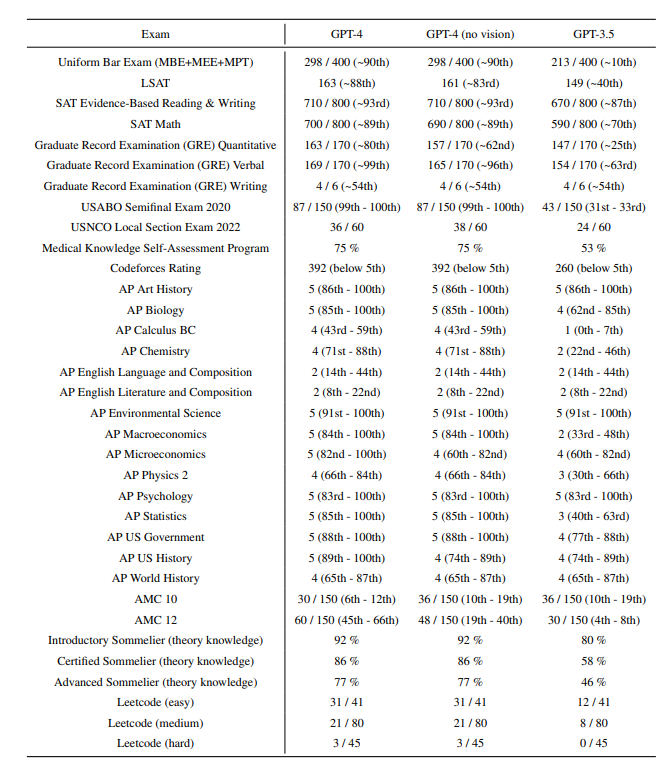
这GRE、leetcode水平,感觉我自己都要花点时间才能达到呢。
academic benchmark
已经叫做benchmark-specific tuning了,面向任务的DL调参侠瑟瑟发抖。
Thinking

这个part让我觉得,训练一个大模型需要好多方面的协调,包括
- Pretraining
- Compute cluster scaling
- Data
- Distributed training infrastructure
- Hardware correctness
- Optimization & architecture
- Training run babysitting
- Long context
- Long context research
- Long context kernels
- Vision
- Architecture research
- Compute cluster scaling
- Distributed training infrastructure
- Hardware correctness
- Data
- Alignment data
- Training run babysitting
- Deployment & post-training
- Reinforcement Learning & Alignment
- Dataset contributions
- Data infrastructure
- ChatML format
- Model safety
- Refusals
- Foundational RLHF and InstructGPT work
- Flagship training runs
- Code capability
- Evaluation & analysis
- OpenAI Evals library
- Model-graded evaluation infrastructure
- Acceleration forecasting
- ChatGPT evaluations
- Capability evaluations
- Coding evaluations
- Real-world use case evaluations
- Contamination investigations
- Instruction following and API evals
- Novel capability discovery
- Vision evaluations
- Economic impact evaluation
- Non-proliferation, international humanitarian law & national security red teaming
- Overreliance analysis
- Privacy and PII evaluations
- Safety and policy evaluations
- OpenAI adversarial testers
- System card & broader impacts analysis
- Deployment
- Inference research
- GPT-4 API & ChatML deployment
- GPT-4 web experience
- Inference infrastructure
- Reliability engineering
- Trust & safety engineering
- Trust & safety monitoring and response
- Trust & safety policy
- Deployment compute
- Product management
- Additional contributions
- Blog post & paper content
- Communications
- Compute allocation support
- Contracting, revenue, pricing, & finance support
- Launch partners & product operations
- Legal
- Security & privacy engineering
- System administration & on-call support
- Pretraining
比较费人的小部门就是data和training部分(标粗显示的部分),然后就是领域专家给反馈(adversarial testers)。
算法部分Pretraining+long context+Vision+RL,测试部署Evaluation+deployment,以及后期各种市场、产品,都缺一不可,都很关键啊。不过能看到AI产品能够有今天,也是十分欣慰了,以前的AI都停留在弱弱弱弱AI的层面吧,好处是觉得自己学的东西真的能改变世界,学科真的有技术爆炸式的飞跃进展,坏处是自己好像没什么用处了(美滋滋,不过发展的尽头,不都是要被替代的吗?语言、教育、设计、律师、计算机、金融各行各业,不论是专业性的,还是需要想象力的艺术生成,好像AI在某种程度上已经击败了90%的人类了吧)。
3年前的自己还很有信念的All in AI,坚信Deep Learning,距离通用AI的出现或许真的不远咯。
目前的AI变强了,但还是辅助人类办公,提升效率的帮手,距离完全代替人类还有很长的路要走(甚至真正的商业化都比较麻烦?)。愈发认为,人类的情感、情绪价值,在当下变得更为宝贵、更难以替代一些。
未来究竟是理性的胜利、还是感性的胜利,是机器的胜利、还是人类的胜利呢。如果有生之年能够见证的话,还挺让人期待的。
不过当下,打不过就加入嘛!