Paper | High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling | ECCV2020
Info
Title:
High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided UpsamplingKeyword:Iterative Inpainting
Idea:利用一个解码器分支预测置信度图,设定阈值,大于0.5的生成结果保存,小于0.5的修复结果舍弃,并进行下一次迭代修复。
Source
- Paper,2020年5月24号arXiv submitted,ECCV2020。High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling (arxiv.org)
- Code,只开源了API接口。iic (zengyu.me)
Abstract
- 以往的图像修复方法通常使用square-shaped or irregular holes,然而在实际场景中,用户想要去除object或scene实例片段(segment)。

- 当时的SOTA方法在真实的Object removal request下效果不佳。

Method
在数据集上,从语义分割、视频分割等数据集收集了82020object mask,并利用random strokes(free-formed mask)和构建的object mask一同训练,避免对于object shaped holes的bias。
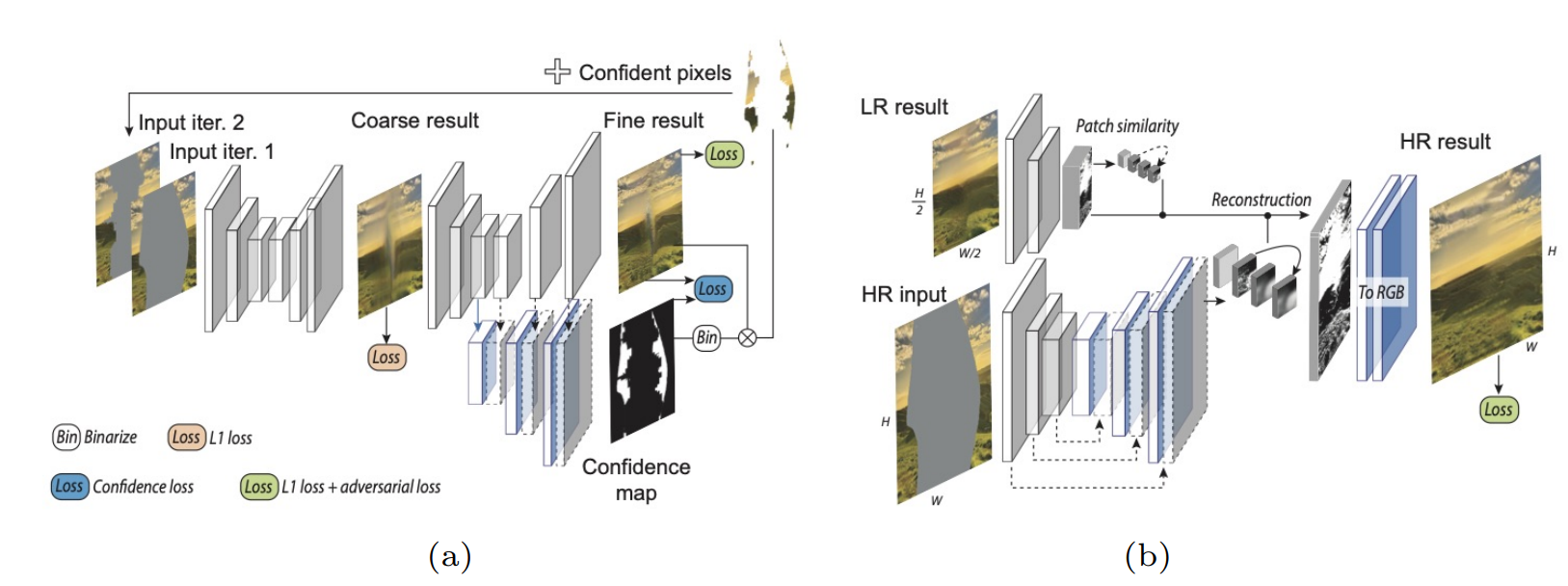
网络使用了course-to-fined架构,精细优化网络有一个编码器和两个解码器,一个生成修复结果,另一个返回预测像素值的置信度图。
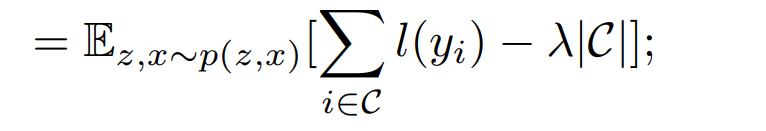
前一项就是对掩膜区域内置信的pixel计算loss,后一项正则来保证置信pixel的数量(其中C代表置信的pixel的集合,如果没有正则,网络偏向于将所有pixel置信度设为0)。设置置信度阈值0.5,低于置信阈值的复原部分不去补全它(不置信),高于阈值的复原部分才补全回去,补全回去后就进行下一次迭代。
参考小尺度补全的patch相似性来进行高分辨率补全。高分辨率的patch feature map由在低分辨率patch计算的相似度来引导。
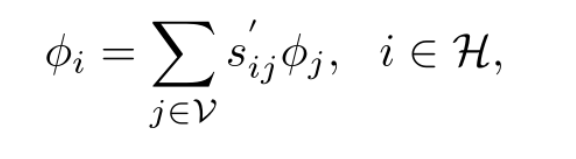
Evaluation
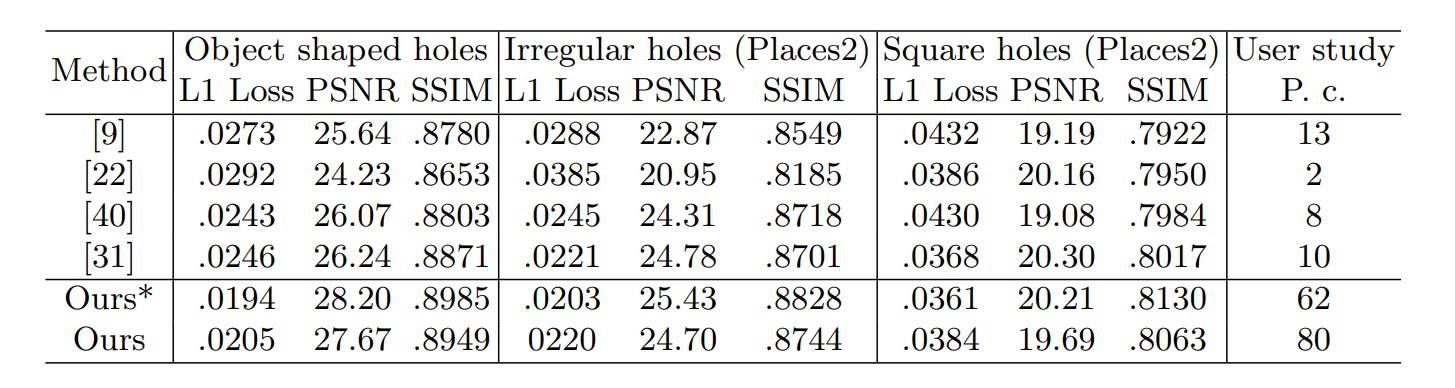
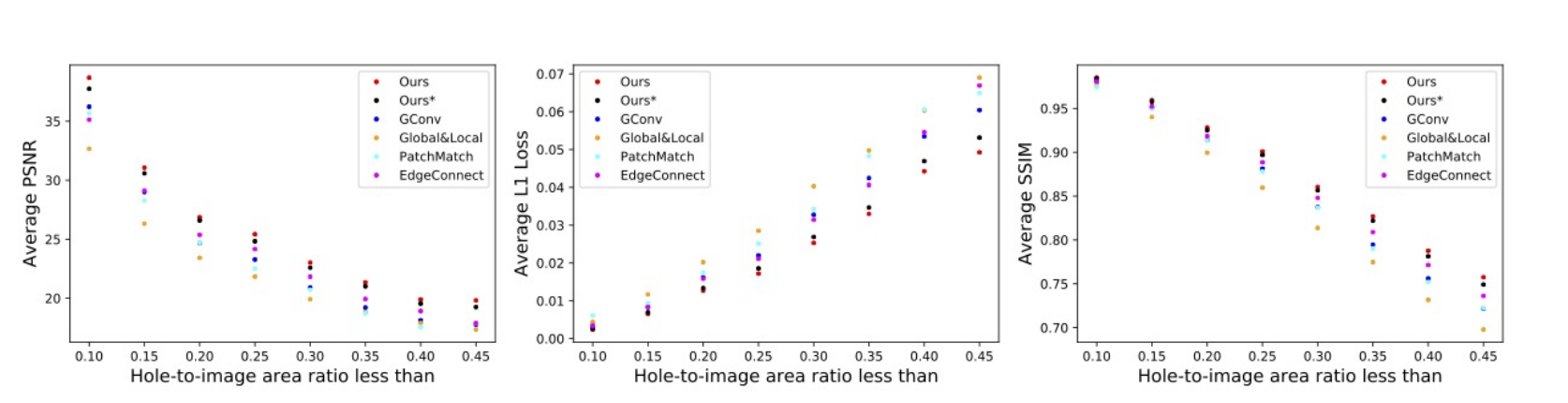
- 在不同缺失区域比例下,超过了当时的SOTA。
Paper | High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling | ECCV2020