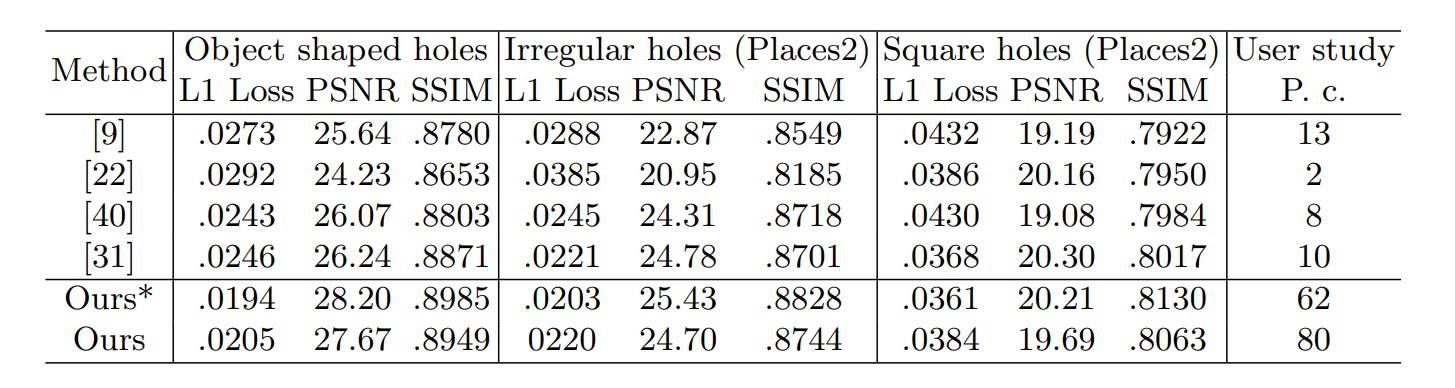
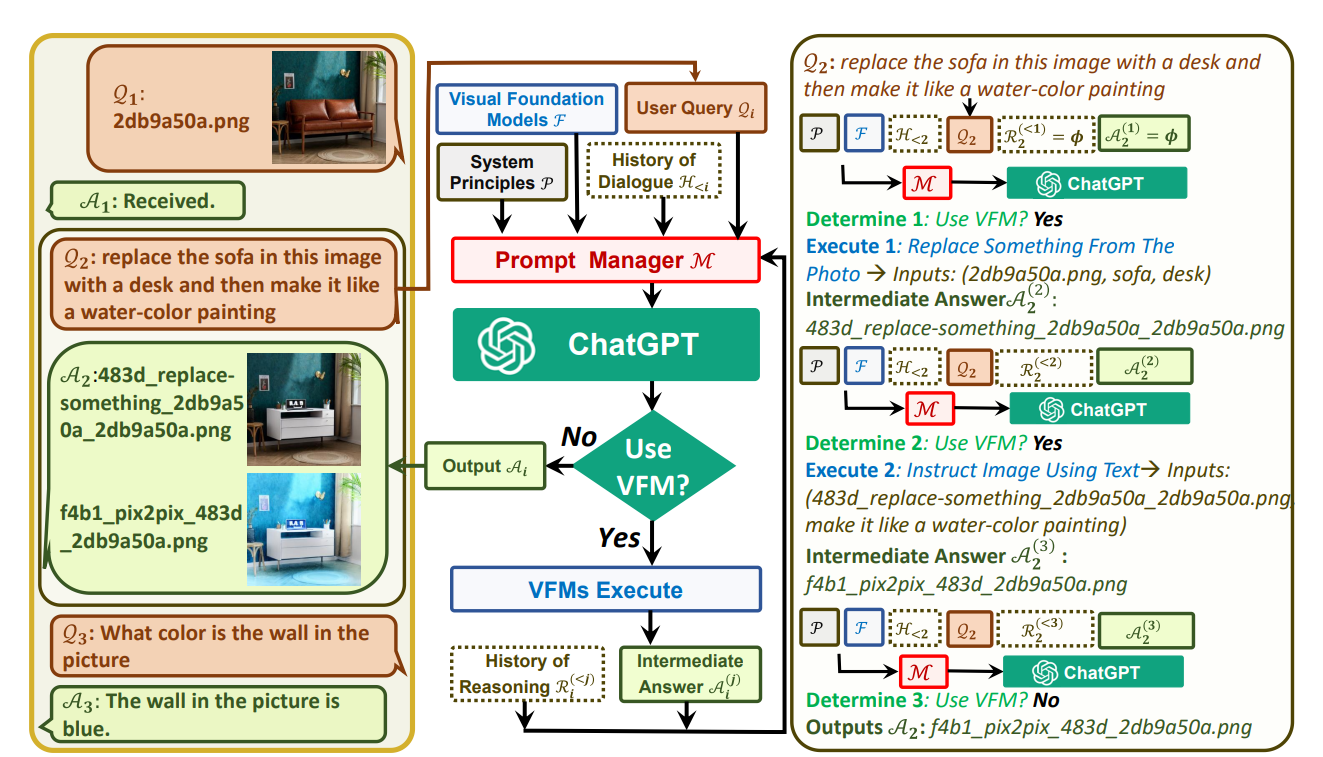
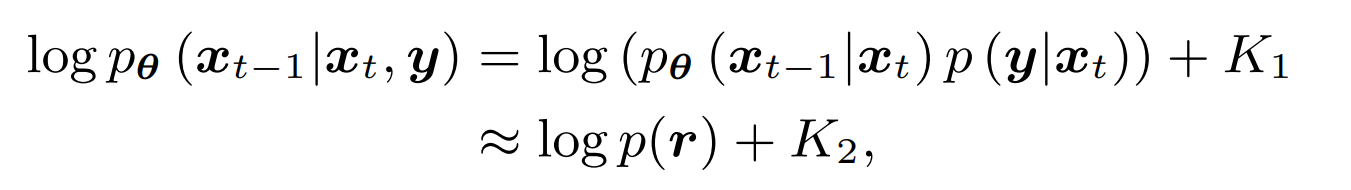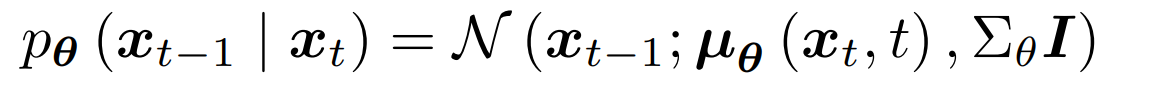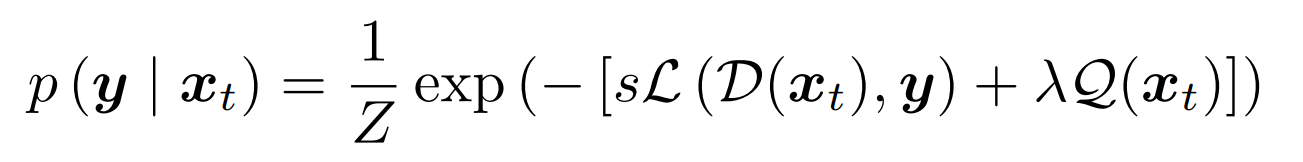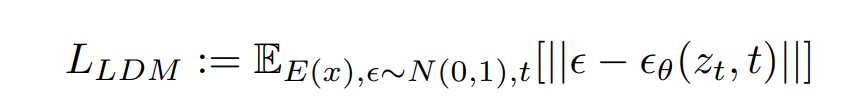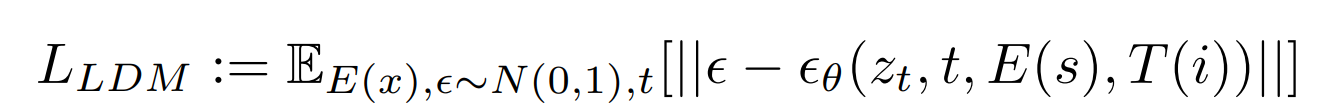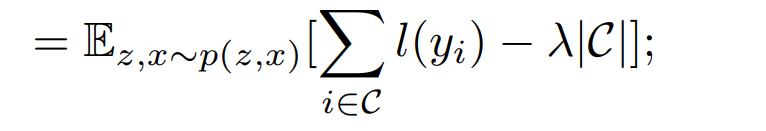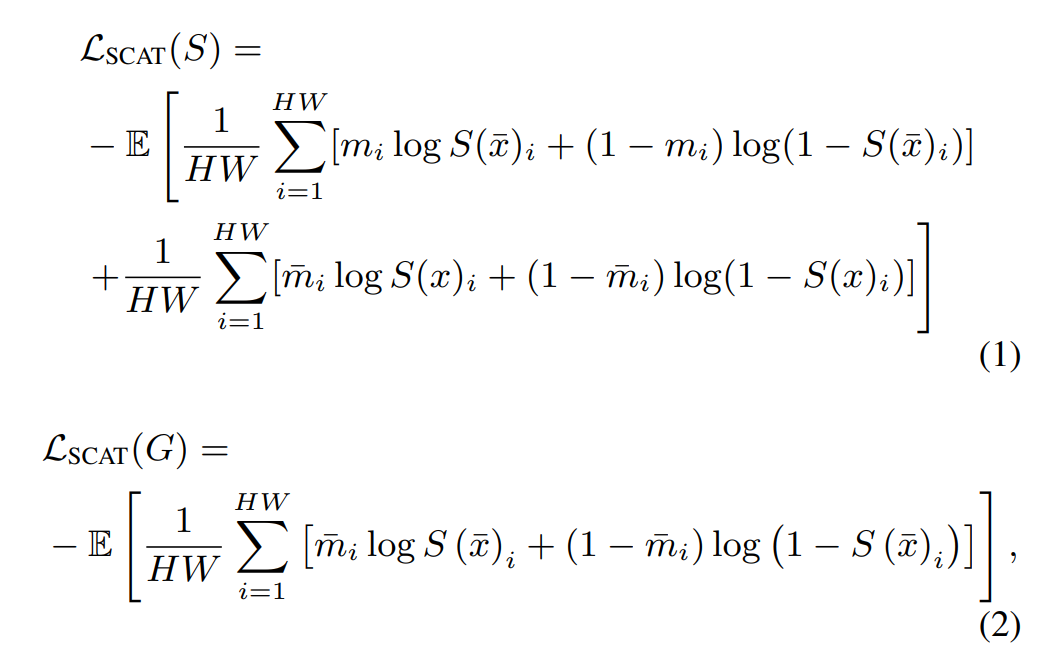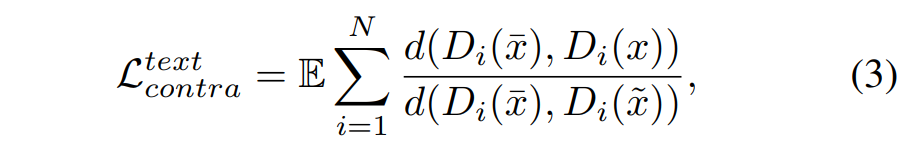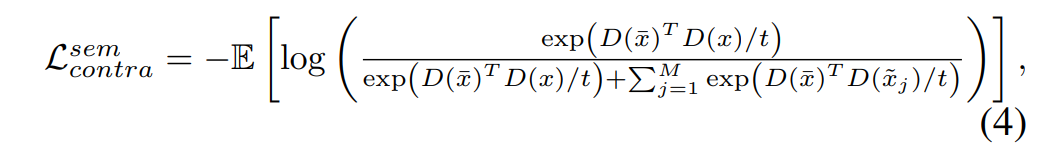Background Knowledge
- inter-class(类间)和intra-class(类内)都是图像分类中的术语,用于描述两种不同的特征。
比如人脸识别任务中用来训练的数据集分为好多不同的人,每个人就是一个类别,每个类别中又有好多单独的图片。
- inter-class代表类别间的特征,比如人脸识别中不同的人脸组件特征之间的差异。
- intra-class代表类别内的特征,比如同一个人在不同状态下脸部的特征的差异(生气和开心的样子肯定不一样)
对于人脸识别任务来说,肯定是希望inter-class特征差异很大,intra-class特征差异很小,这样我们的模型才能更好的识别不同的类。
Info
- Title:
SDD-FIQA, Unsupervised Face Image Quality Assessment with Similarity Distribution Distance - Keyword:Face Image Quality Assessment,Distribution Distance
- Idea:利用类内相似度分布和类间相似度分布之间的Wasserstein距离生成人脸图像质量伪标签。
- Source
Abstract
存在的问题:
- 大多数基于人脸识别特征的方法只考虑了部分的类内信息,忽略了类间信息。作者认为一张高质量的人脸图片应该与其同类样本相似而与类外样本不相似。
解决方法:
- 提出一个新的无监督FIQA方法,利用类内相似度分布和类间相似度分布之间的Wasserstein距离生成人脸图像质量伪标签。然后,利用这些质量伪标签进行无监督人脸质量回归网络训练,从而获得一个质量评估模型。
Method
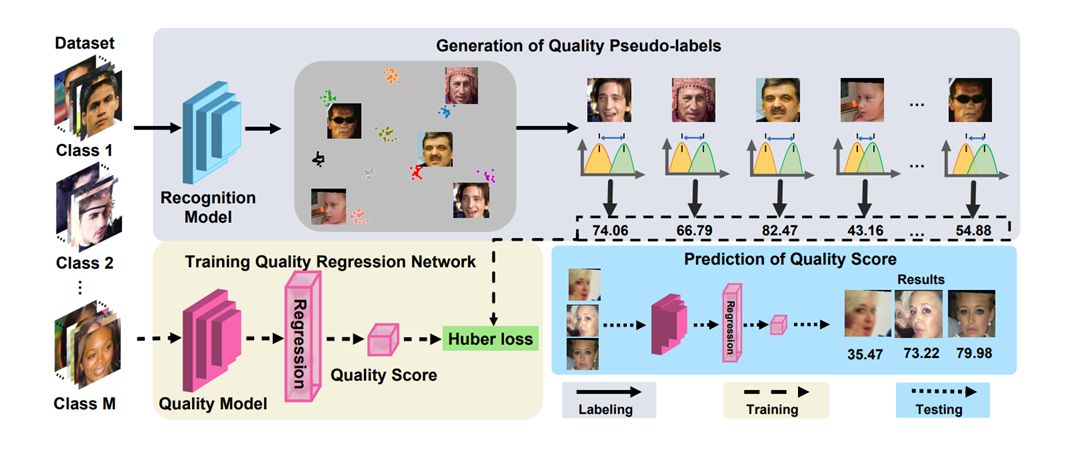
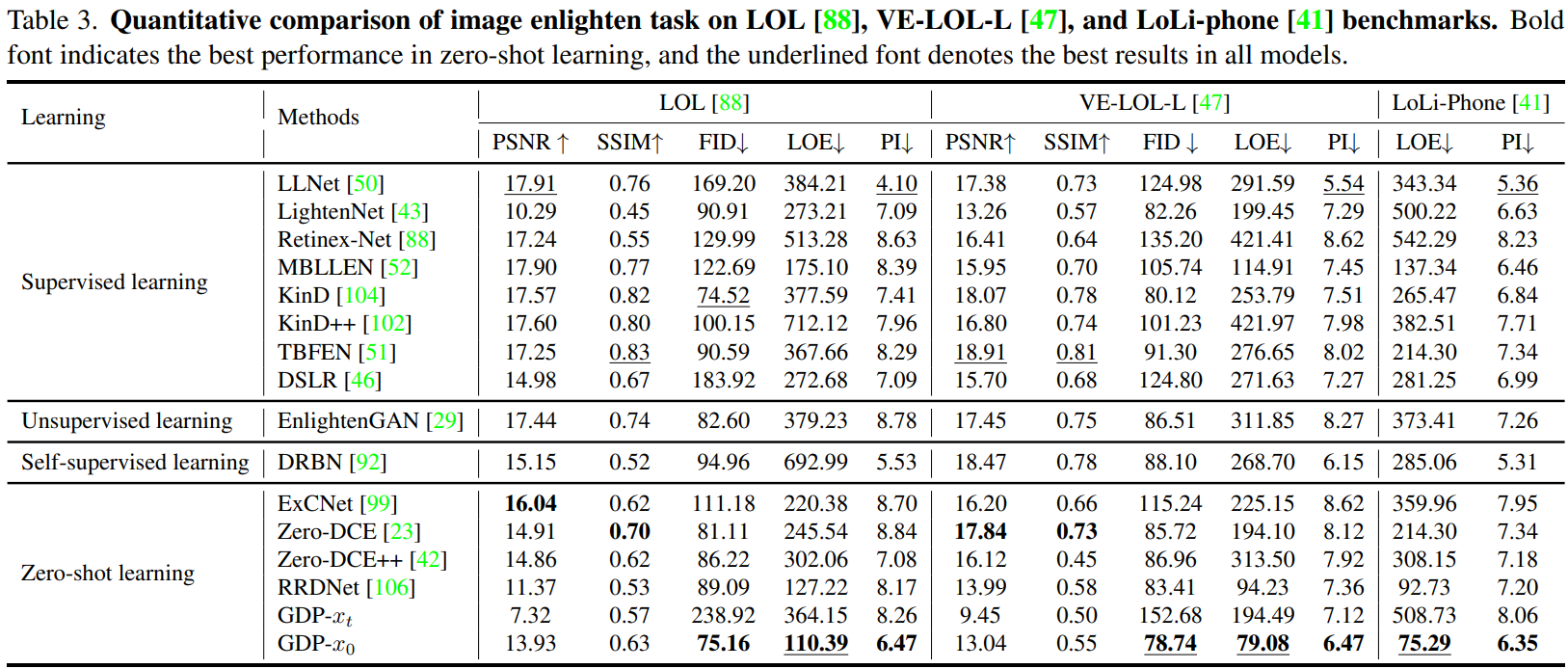
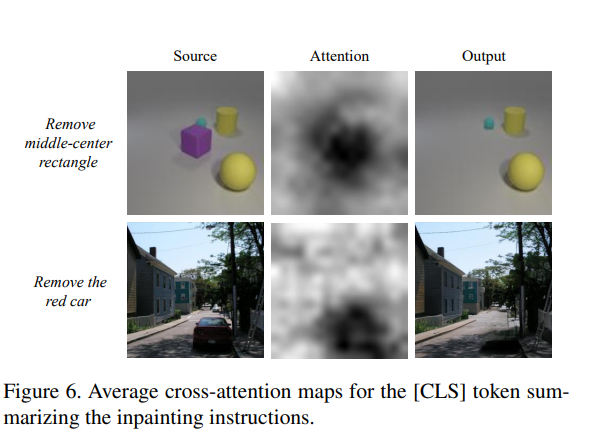
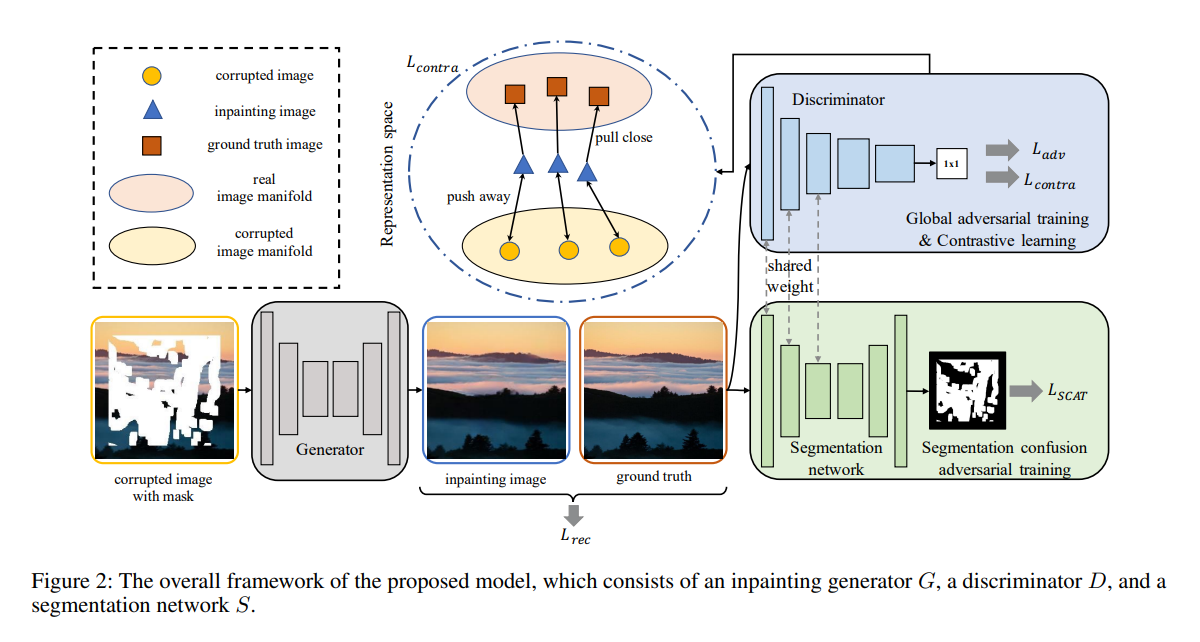
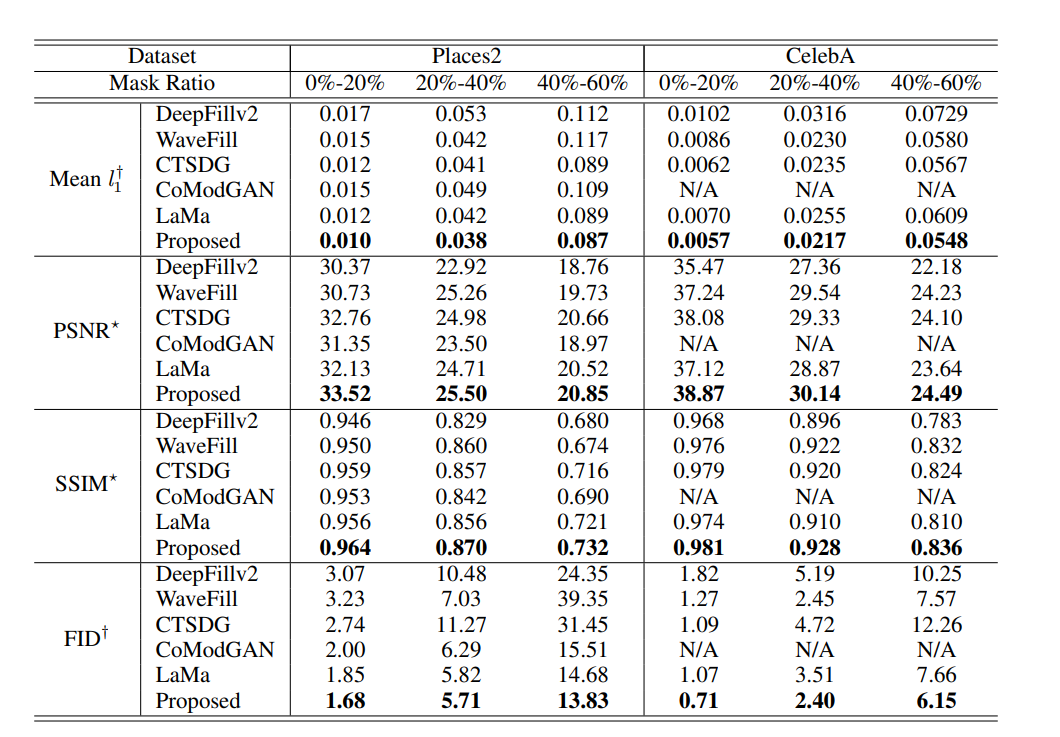
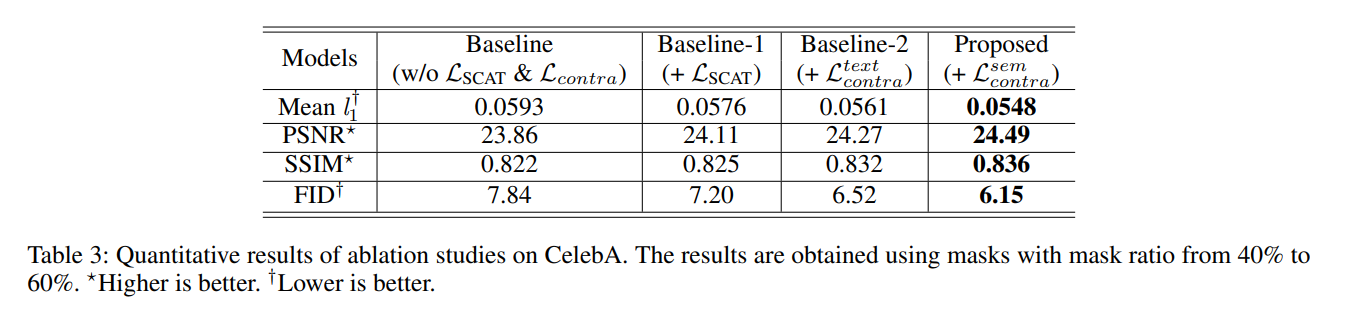
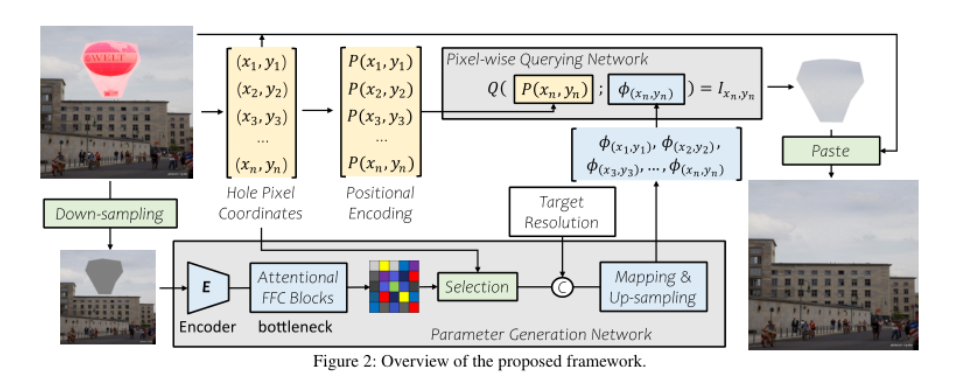
从人脸识别效果来看,一张高质量的人脸图像更容易被识别正确,这表示它与类内的相似性距离较近,与其它类间的相似性距离较远。换句话来说,它的类内相似性分布与类间相似性分布距离较远。图像质量与类内-类间相似度距离如下图所示,低质量人脸WD距离较近,高质量人脸WD距离较远。
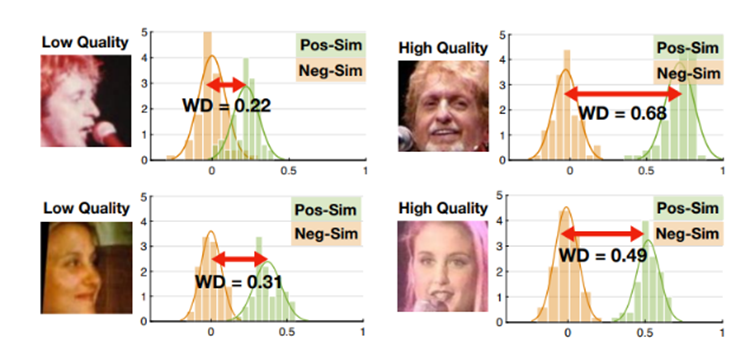
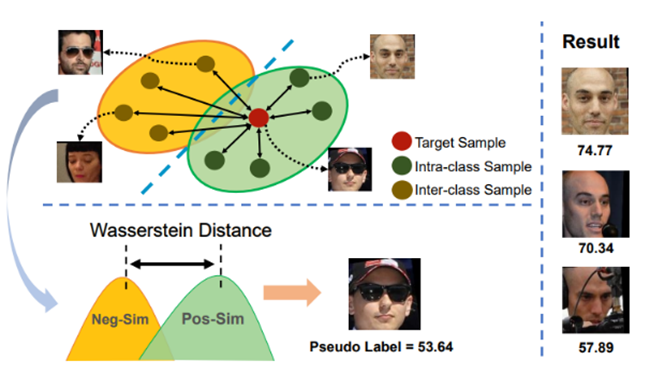
图中红点表示目标样本,绿点表示类内样本,黄点表示类间样本。类内相似性分布(Pos-Sim)与类间相似性分布(Neg-Sim)的WD距离为质量分数伪标签,质量分数结果如图中右侧所示。
假设X,Y,F分别表示图片集、id标签集、识别特征集,构建一个三元组数据集。
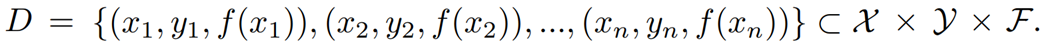
利用同一个id下的两个样本构建正样本对(intra-class,类内),不同id的两个样本构建负样本对(inter-class,类间),对于每一个训练样本
,正样本对和负样本对的相似度集合分别为: 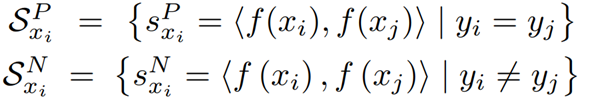
其中尖括号中的内容代表了两个样本的识别特征嵌入空间中的余弦距离。
文章使用Wasserstein距离度量正样本相似度和负样本相似度分布情况。

- 使用生成的质量分数标签训练质量回归网络。在训练过程中利用人脸识别模型进行知识迁移,提升质量回归模型的预测结果与识别的匹配度。去掉embedding和原来的分类层,添加一个FC层,采用dropout方式防止训练过程中过拟合,使用Huber loss回归损失函数训练质量回归网络。相比MSE,Huber损失对数据中异常值更具鲁棒性。
Evaluation
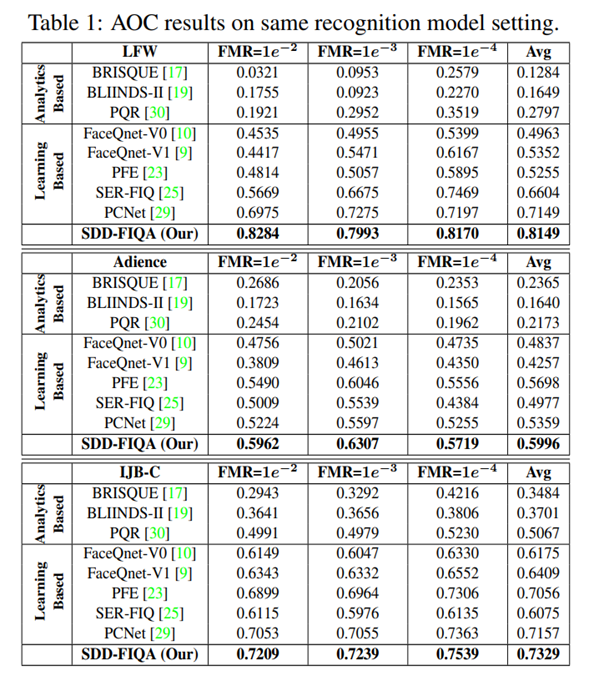
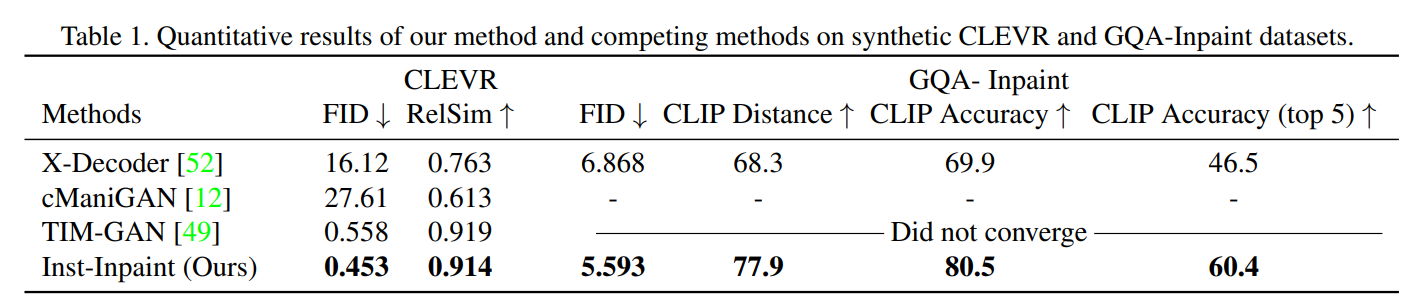
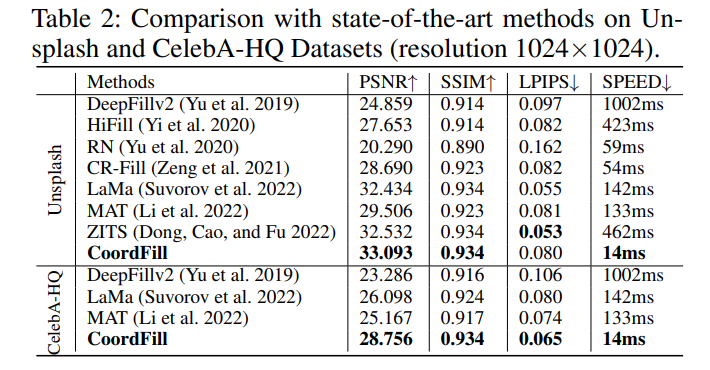
- 结果为质量回归模型与人脸识别模型均采用ResNet50-MSIM的结果,表中结果显示使用SDD-FIQA质量评估后,在固定误识率(FMR)下,人脸识别结果在LFW、Adience、IJB-C三个数据集上均优于目前最好的质量评估方法。