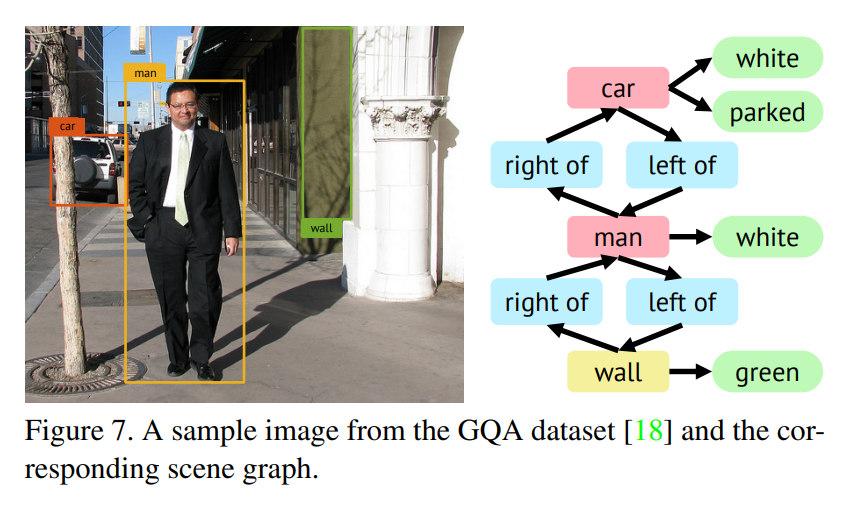
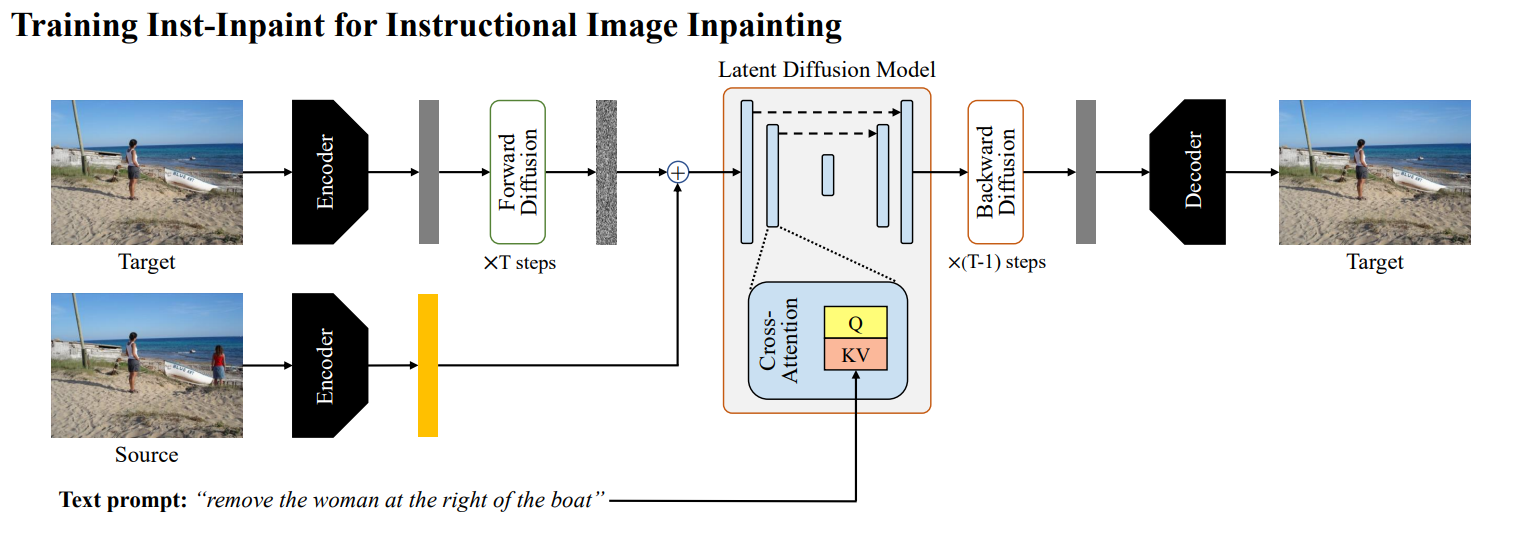
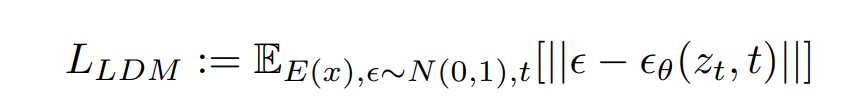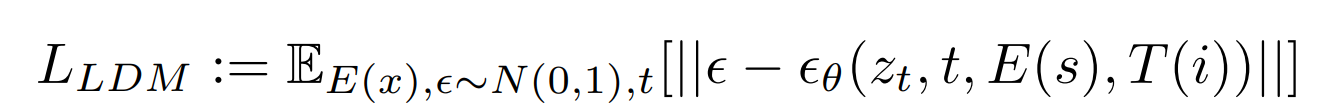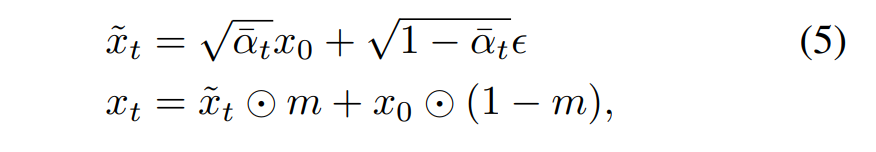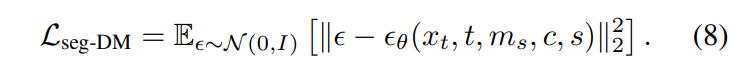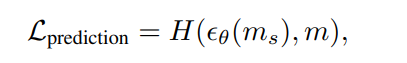All human progress is about overcoming an obstacle. From the wheel to the internet, we have discovered and invented our way out of all sorts of trouble. The story of science and technology is, in the main, one of making our lives easier.
Instead of talking out of both sides of our mouths, perhaps it is time that we were appreciated just how much we need technology, and how far it has helped us along. That is exactly what philosopher John Danaher does in his recent paper, Techno-optimism: an Analysis, an Evaluation and a Modest Defense.
Obviously, technology is not perfect. Smart phone addiction does exist, environmental destruction is happening, and we are each seeing a rapid, abrupt uprooting of how society has operated for millennia. If we say we’re “techno-optimists,” we are not saying that we are blind to technology’s problems. Optimism is not fanaticism.
Instead, as Danaher argues, optimism is defined by three elements. First, optimists believe “the good prevails over the bad by some distance, with that distance varying depending on the strength of the optimistic stance.” So, in terms of technology, it means the good outweighs the bad.
Second, optimism tends to associate with an “affirmation of improvement.” The year 2022 is a better time to live than 1880 — or even 1980.
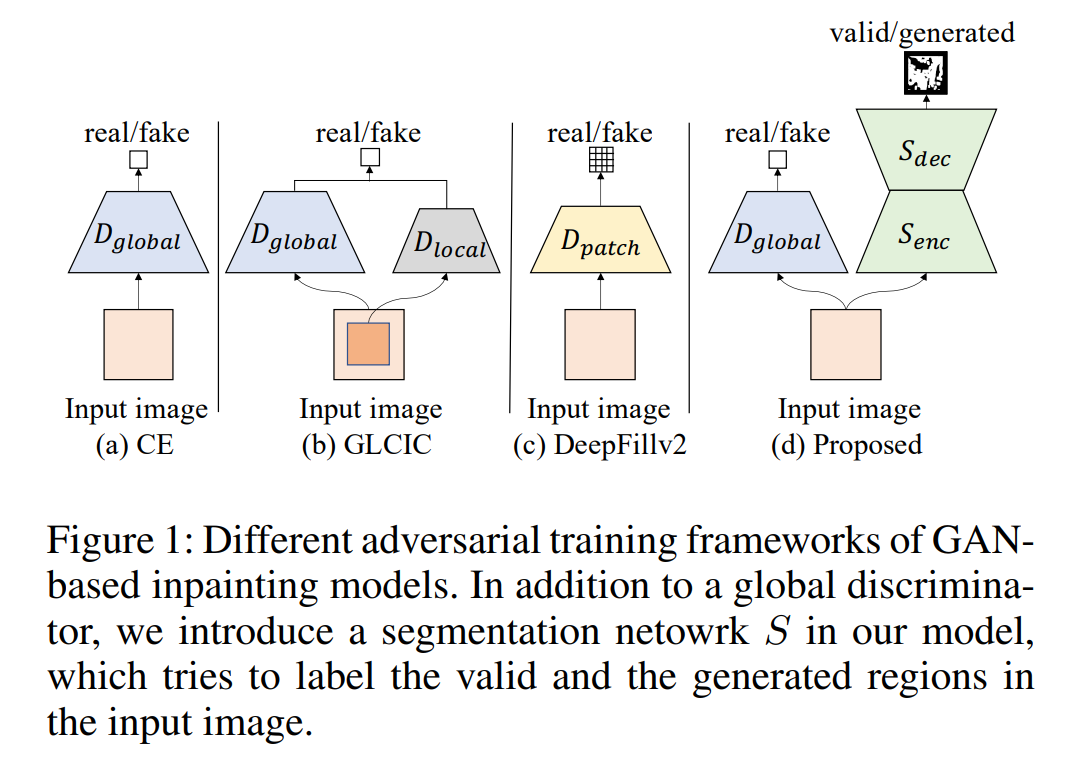
Third, optimists (and pessimists, for that matter) must believe that we can actually measure “good” as a value to track. We can point to this or that technology and say, “These are examples of good things that could only be caused by technological improvement.”
According to Danaher, in order to properly justify and rationalize techno-optimism, we must do three things: Establish values, determine facts, and evaluate.
Establish values. First, we must establish certain values as being “good.” For instance, a techno-optimist “might argue that it is wonderful that people have more disposable income and a richer set of consumer goods and services from which to choose.”
Determine facts. Once we have established these values, then we have to present those facts that support the claim that technology provides them.
Evaluate. We need to present the facts that defend values, but we also need to acknowledge facts that contradict those values as well. As mentioned above, technology does have its problems. It can impact our mental health, it ravages the environment, and it drastically upends what being human has always meant. The techno-optimist is the one who believes the good of technology outweighs the bad.
There are two major critiques of techno-optimism that Danaher addresses.
First, the “treadmill critique” argues that technology won’t constantly make the world better. We have become so accustomed to technology that we no longer appreciate it as “good” but rather expect it as the norm.
Danaher counters by suggesting that there exists some “values that are not subject to baseline adaptation.” He cites “longer lives, fewer life-threatening illness, and more equality of opportunity” as examples of “goods” that will always be good, regardless of how accustomed we are to them.
Second, the “unsustainability critique” is the idea that if “optimism depends on present or continued economic growth, it also depends on the continued technological exploitation of natural resources. All natural resources are finite and have some upper limit of exploitability.”
Danaher’s response is that “technology is becoming less exploitative over time.” As a technology improves, then growth “decouples” from exploitation.
You do not have to adopt a starry-eyed “technology-will-save-humanity” viewpoint to be a techno-optimist. It’s perfectly reasonable to suggest that there are many existing problems with technology, and that it, alone, is insufficient for good to prevail.
Instead, we might sympathize with Danaher’s “modest techno-optimism.” According to this view, “we have the power to create the right institutions for generating, selecting, and creating material technologies, and acting on that belief in a cautious and sensible manner can make it more likely that the good will prevail over the bad.”
It’s a kind of techno-optimism that perhaps needs a bit of human optimism, too.