Info
- Title:
ZITS++: Image Inpainting by Improving the Incremental Transformer on Structural Priors - Keyword:Transformer, High resolution Image Inpainting
- Idea:之前CVPR2022会议文章的期刊版本,做了一些小改进和其他的尝试。
- Source
- Paper,2022年10月第一版,2023年2月23日第二版(新鲜出炉的)。2210.05950] ZITS++: Image Inpainting by Improving the Incremental Transformer on Structural Priors (arxiv.org)
- Code,DQiaole/ZITS_inpainting: Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (CVPR2022) (github.com),Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (dqiaole.github.io)
Abstract
ZITS存在的问题:
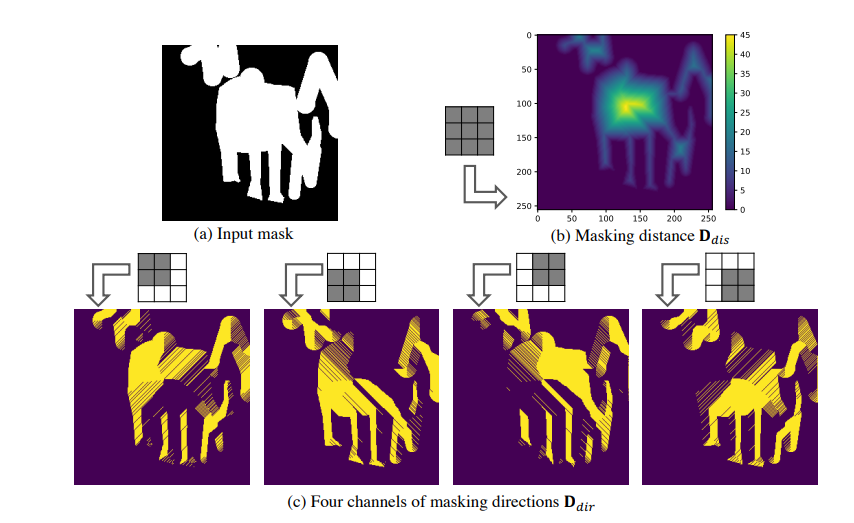
- ZITS中使用的canny边缘不能区分有意义的结构。在复杂环境中Canny边缘产生confusing textures而不是具有丰富信息的底层结构。

- 深入研究不同的图像先验信息引导的高分辨率图像修复是必要的。
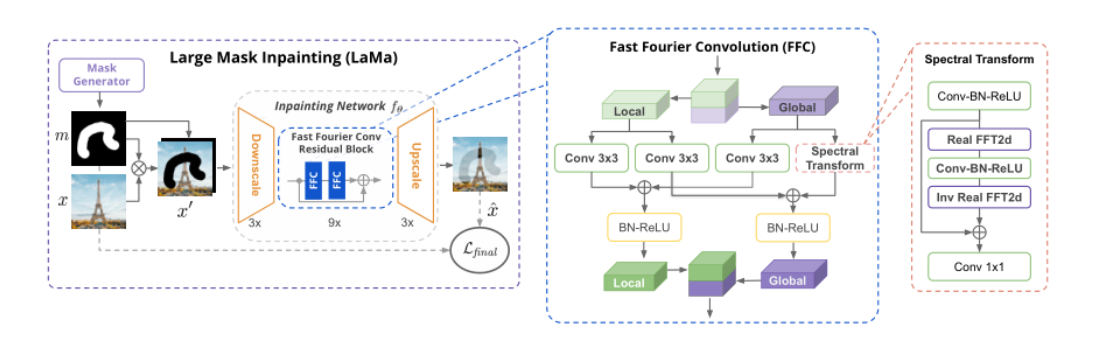
- 提升LaMa的纹理修复性能。
贡献点:
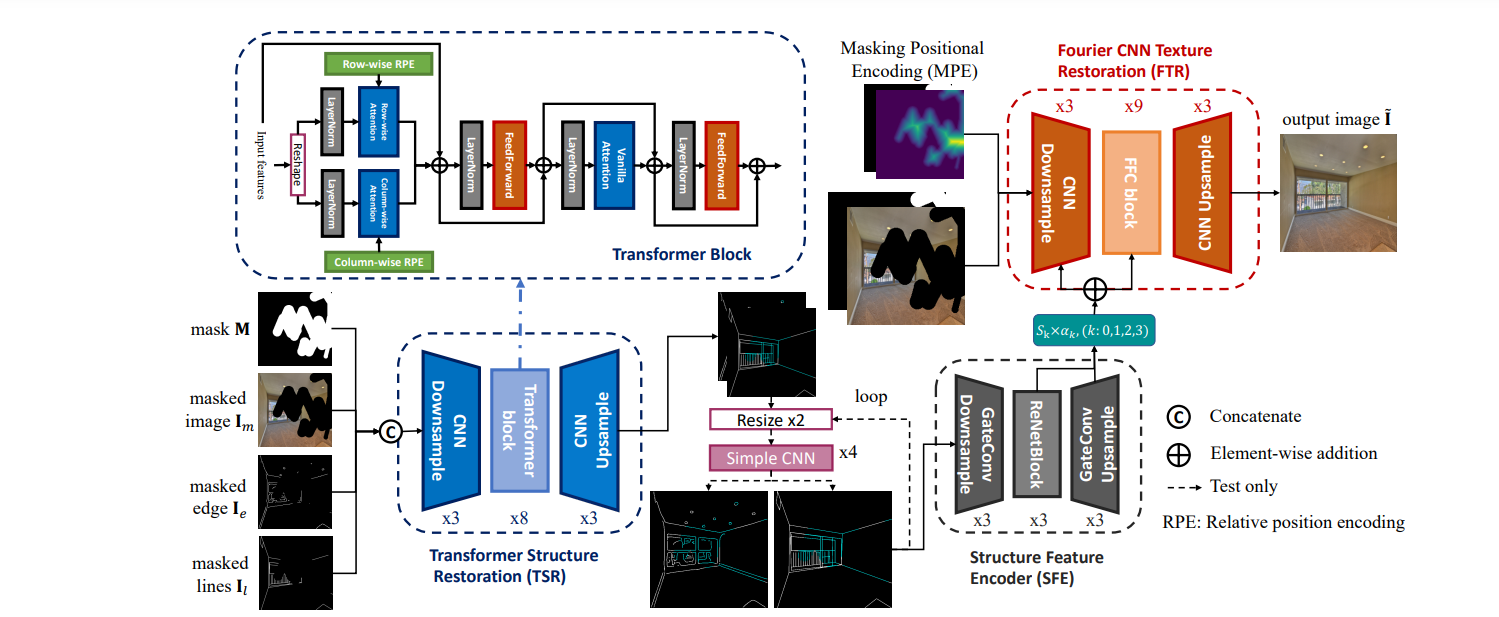
- 在原始的ZITS上(transformer-based的边缘和线框补充),又加入了许多不同先验的实验分析和讨论,最终发现L-Edges、线框和梯度先验结合效果最好。
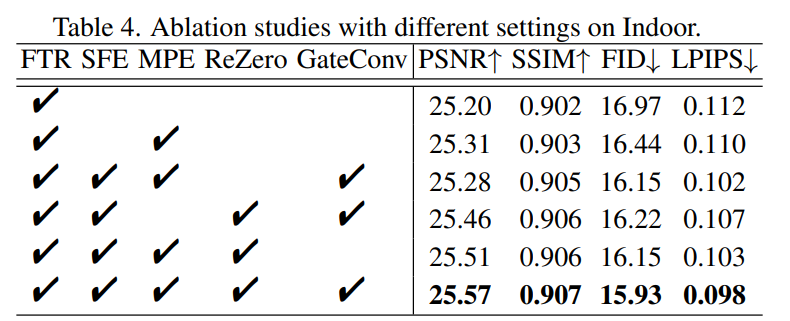
- 将补全好的先验信息融合到修复网络中需要上采样,提出了一种Edge Non-Maximum Suppression(E-NMS),将冗余的边缘信息过滤掉(消除边界附近的模糊边缘)。
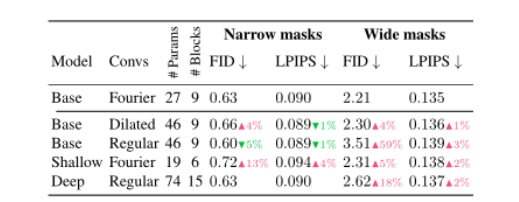
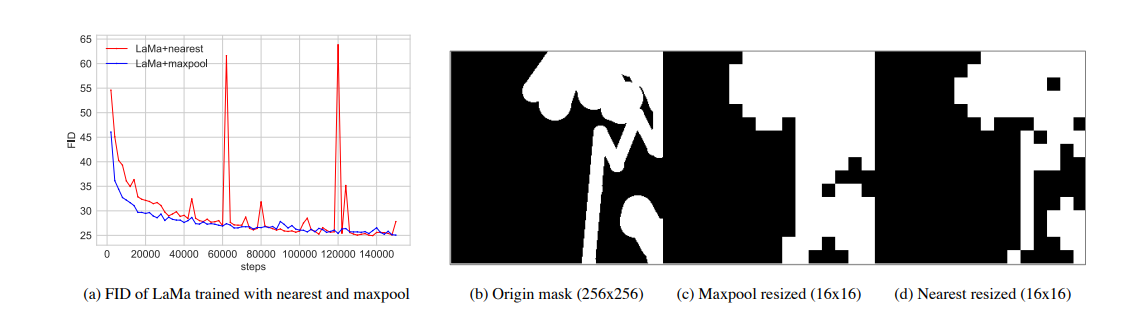
- 对于LaMa进行修改,加入了Large Kernel Attention以及修改模型设计。(增益:large receptive fields and scale invariance尺度不变性。we promote the maxpool as the mask resizing strategy of PatchGAN instead of the nearest in LaMa)

- 提供了一个高分辨率图像数据集,HR-Flickr。
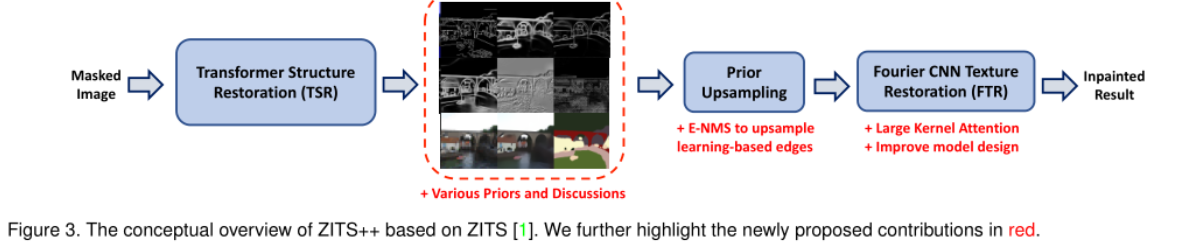
Method
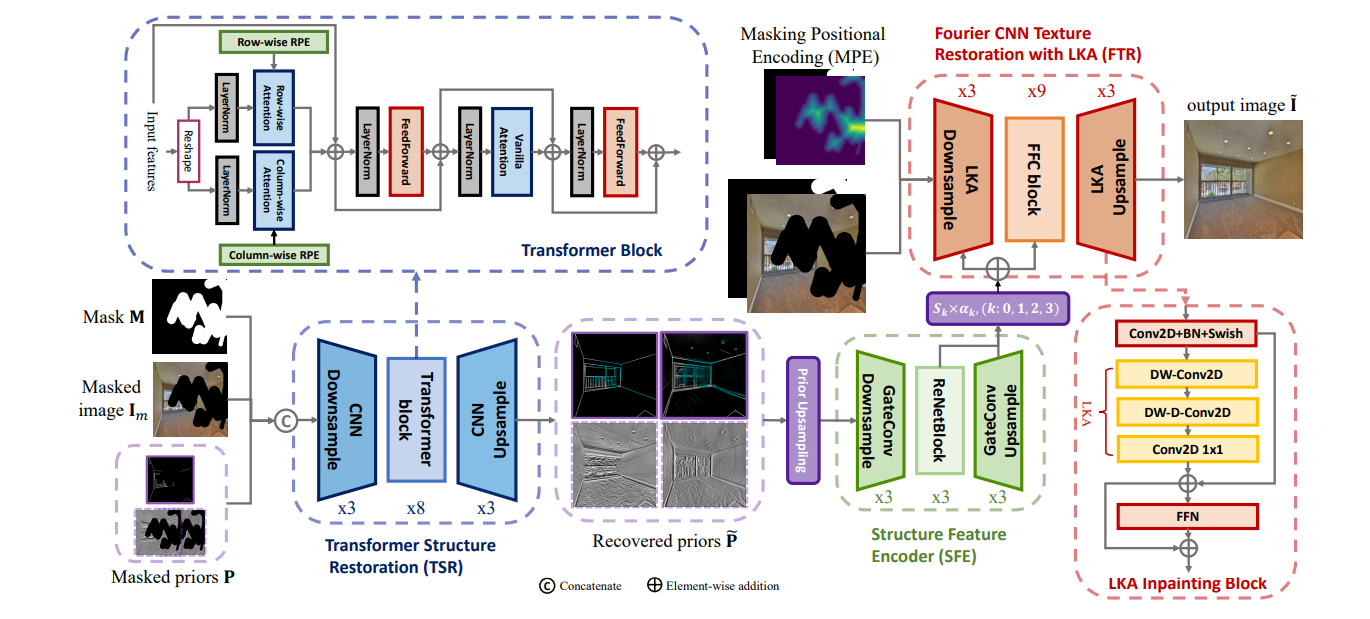
- 提出了learning-based边缘CATS取代原来用的canny边缘。并利用E-NMS(现有的算法)过滤不确定的边缘。最终使用的先验是CAT+线框(wireframe)+梯度。

利用扩张卷积分解large Kernel,实验中取K=21。
mask resize策略:maxpool取代nearest resize(稳定训练过程)
Evalutaion
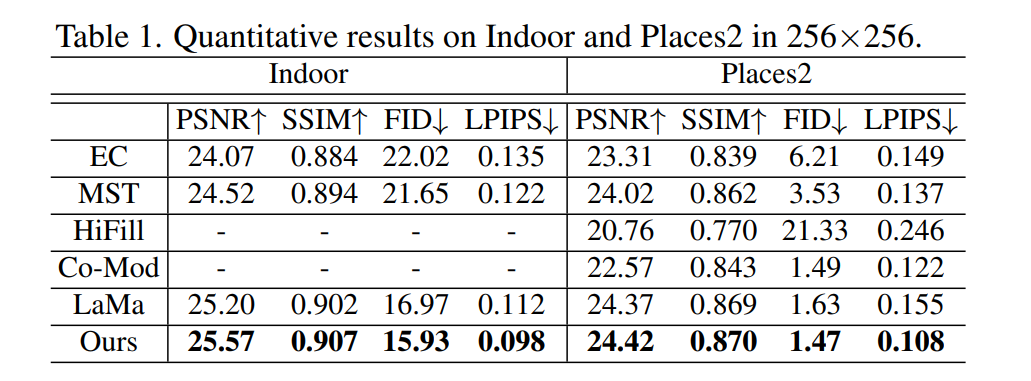
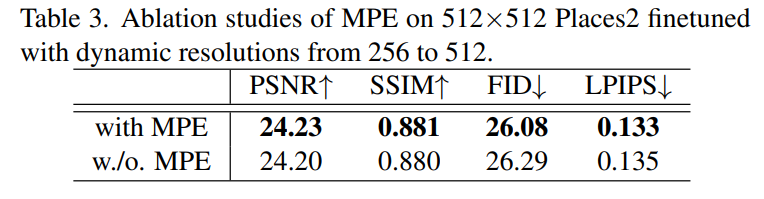
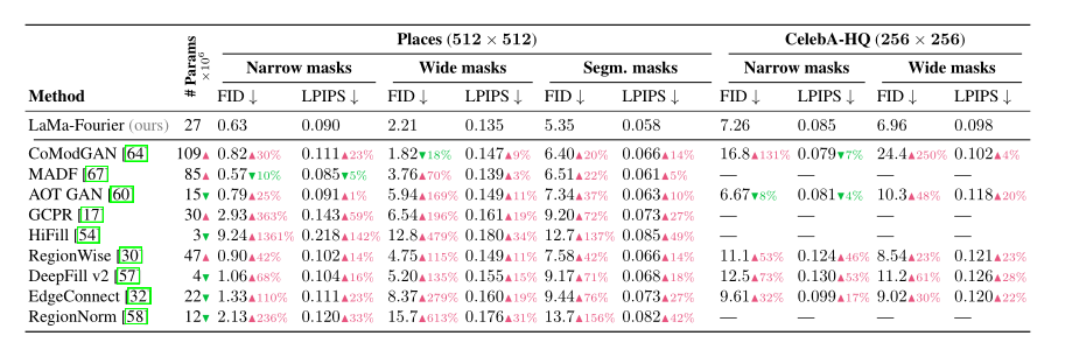
- 定量性能提升明显。
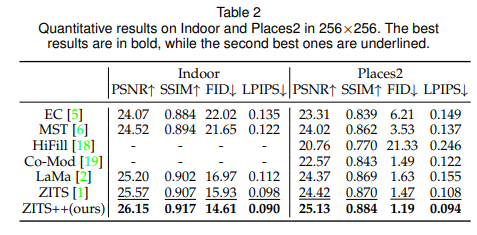
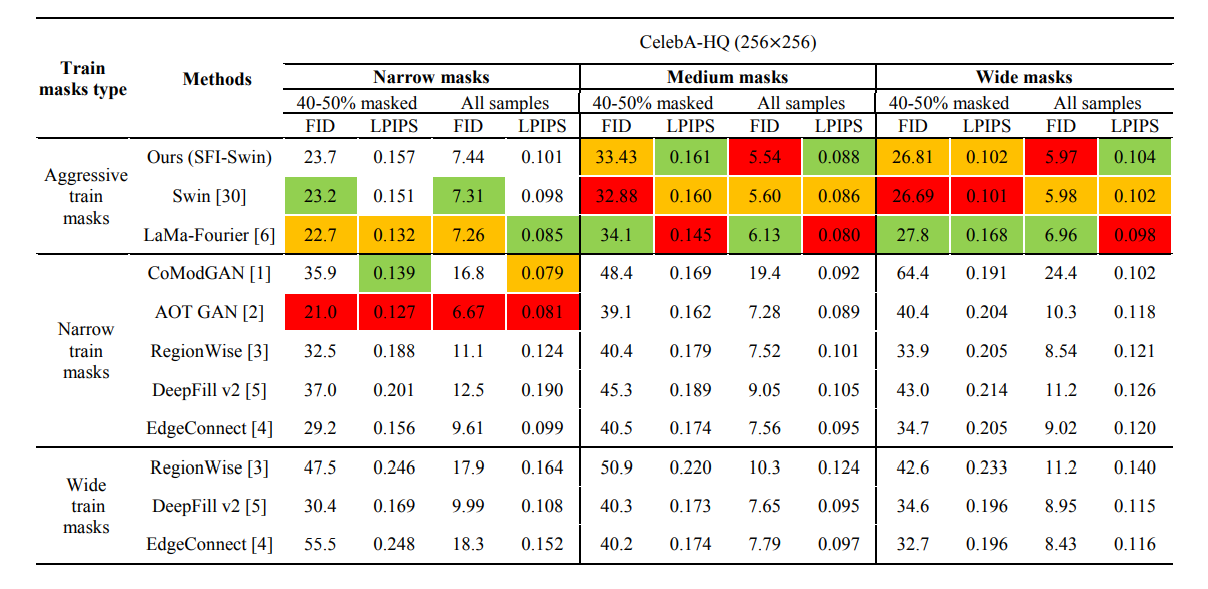
- 定量效果也很好。
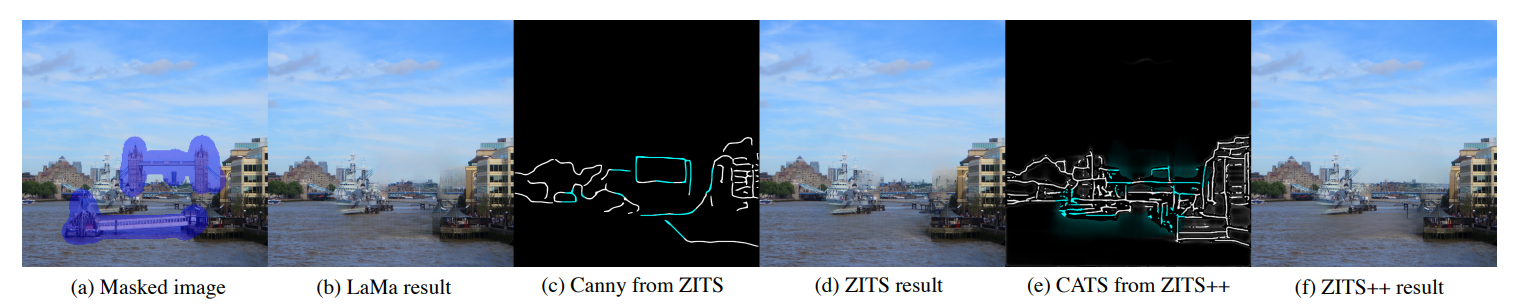
- 人脸修复效果也很好。