Paper | Inst-Inpaint, Instructing to Remove Objects with Diffusion Models | arXiv2023
Info
- Title:
Inst-Inpaint: Instructing to Remove Objects with Diffusion Models - Keyword:Object Removal、Inpainting、Diffusion Models
- Idea:利用Text prompts(Instructions)进行图片中的物体去除,并填充背景内容。
- Source
- Paper,2023年4月6号arXiv submitted,CVPR2023投稿(贡献点不足、实验不充分、不够创新,InstructPix2Pix用作图像编辑其实已经涵盖了本文提出的内容)。Inst-Inpaint: Instructing to Remove Objects with Diffusion Models (arxiv.org)
- Code,Coming soon。abyildirim/inst-inpaint: A novel inpainting framework that can remove objects from images based on the instructions given as text prompts. (github.com)
Abstract
现存的问题:
- 现有的Inpainting任务都是填充二值掩膜(binary masks)区域的内容。现实应用时需要用户的标注,这浪费时间、乏味并且容易出错。

解决方法:
Instructional Image Inpainting:本文提出一种基于自然语言输入(natural language input)的目标移除的任务。
Dataset:为Inst-Inpaint构建了一个命名为GQA-Inpaint的数据集(原始source image、目标移除text prompt、目标移除后的target image三元组)。
Method:Remove objects from images based on the instructions given as text prompts。基于latent diffusion的有条件移除(Stable Diffusion有条件生成可以迁移到Inpainting任务,但是生成性能较好,面对移除问题时not work that well)。
Method
Dataset Generation

- 在GQA数据集(visual reasoning)上创建benchmark数据集GQA-Inpaint,利用GQA数据集提供的场景关系图、以及sota实例分割模型和Inpainting模型来生成数据。
- scene graphs:object、attribute、relation三元组,85K pairs。每一个结点代表一个物体,位置和大小会有bounding box标出;attribute包括color、shape和material;relation表示了空间位置。
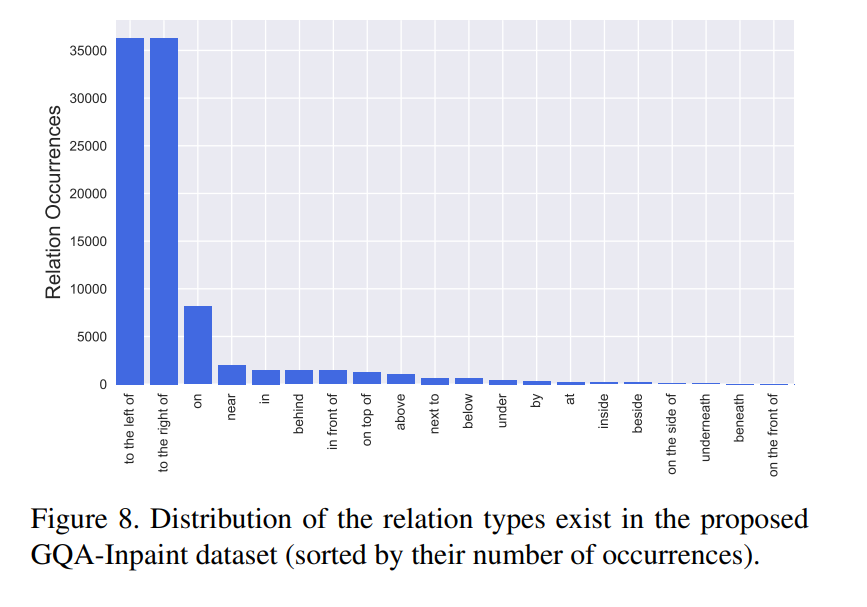
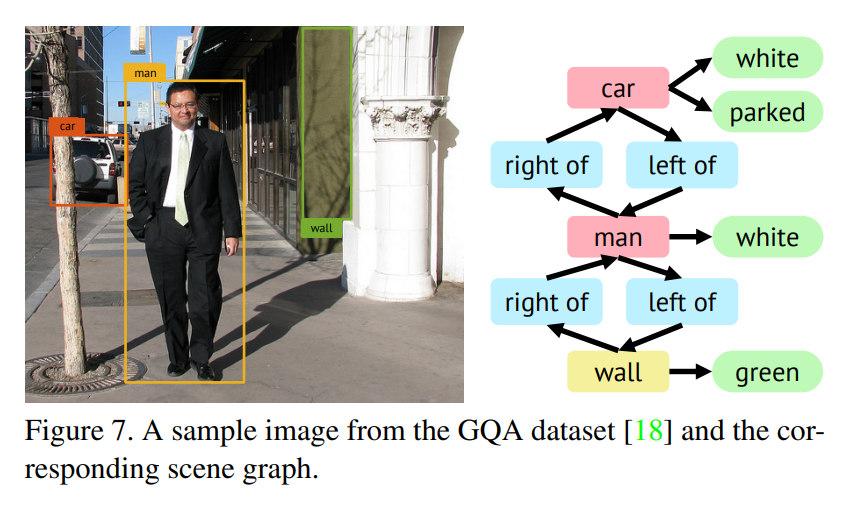
Selecting Objects from the Scene Graphs
选择数据集中较常见的target objects,避免选择bounding box过大或过小的物体。
Extracting Segmentation Masks
基于Detectron2 code base,利用多个在COCO和LVIS数据集上的实例分割进行seg mask的提取,取和原始数据集bounding box IoU最大的mask。
Removing Objects From Images
利用Cascade PSP模型refine预测的seg mask,再利用结构元素为11×11像素的形态学扩张在边缘处展开seg mask。最后使用CRFill模型进行填充。

Generating Textual Prompts
如果选择的物体在图像中是一个unique实例,不存在关系问题,生成简单text prompt“remove the [object]”
如果存在多个实例是同一个物体类别的,使用scene graph中的关系信息来构造具有相对位置的text prompt。
Model
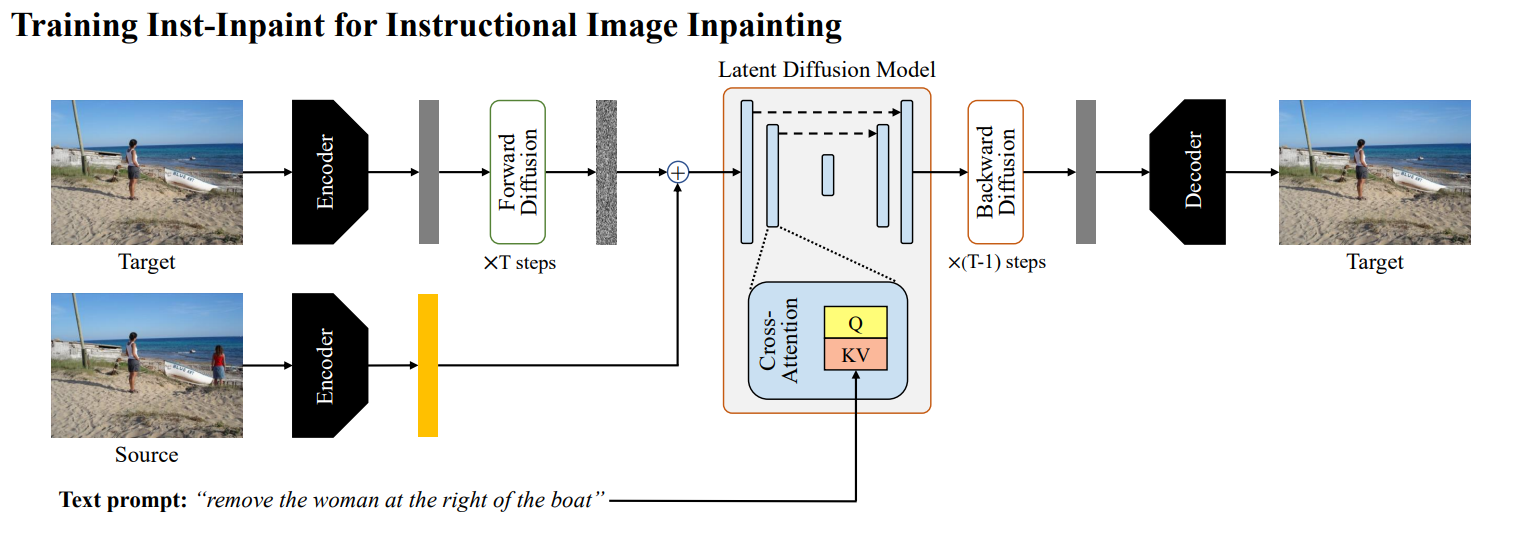
- 第一步是独立训练变分自编码器,encoder、decoder来将图像降到低维并重建。
- 加噪去噪的过程和Stable Diffusion相同架构。
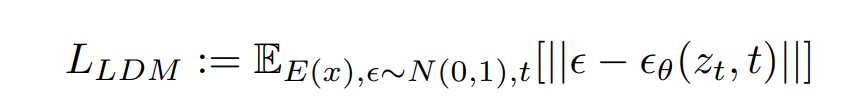
- additional conditioning:source image、text prompt
- 利用target图片(移除物体后的)经过encoder获取
。每一个time stepsource image也通过编码器作为额外的条件输入和 concat。 - T是transformer model,i为文本instruction。利用BERT tokenizer生成token,训练一个transformer model from scratch来获取instruction embeddings,供U-Net layers中的cross attention mechanism使用。
- 利用target图片(移除物体后的)经过encoder获取
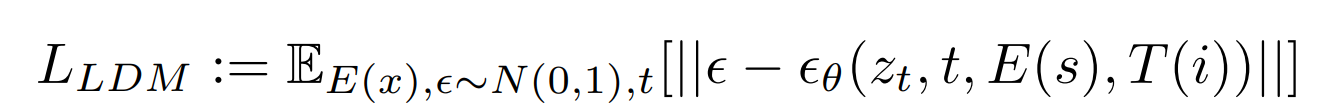
训练细节
- 在CLEVR(三维物体编辑数据集,包括source/target image和text)、GQA-Inpaint上训练了模型(5405train、2362test)。
- GQA-Inpaint(训练使用44500unique source images、88369unique target images、173715 unique source-target-prompt pairs;测试使用4811 unique source images、9485 unique target images、18883 unique source-target-prompt pairs)
- CLEVR的VAE是从零训练,GQA-Inpaint的VAE使用pretrained VQGAN模型(在Open Images数据集上训练的, has 16384 number of codebook entries)
- CLEVR使用八层transformer、4-head cross attention和activation layers。GQA-Inpaint使用16层transformer、8-head cross attention。
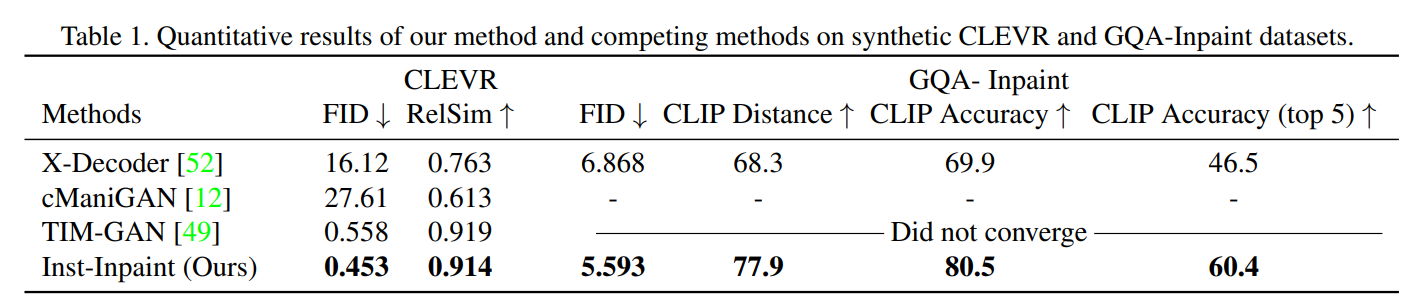
对比的一个Instruct X-Decoder生成分割图然后进行物体移除,结合了X-Decoder的图片理解能力、GPT-3的语言理解能力和stable diffusion的生成能力。(训练数据集比提出的GQA-Inpaint 大很多)
模型方面,和Stable Diffusion的区别就是输入图像没mask区域,指令是source image需要移除部分的text prompts。
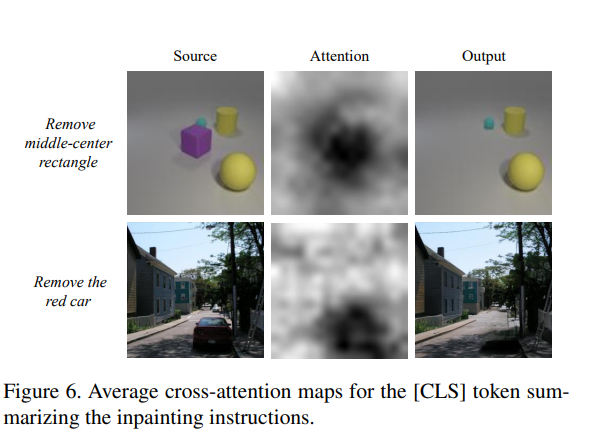
Evaluation





Paper | Inst-Inpaint, Instructing to Remove Objects with Diffusion Models | arXiv2023