Paper | SmartBrush, Text and Shape Guided Object Inpainting with Diffusion Model | CVPR2023
Info
Title:
SmartBrush: Text and Shape Guided Object Inpainting with Diffusion ModelKeyword:Diffusion Model for Inpainting
Idea:利用实例分割mask和文本标签(实例分类或BLIP生成的长句描述)进行精细的Object Inpainting。
Source
- Paper,2022年12月9号arXiv submitted,CVPR2023。SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model (arxiv.org)
- Code,未开源。
Abstract

现存的Diffusion-based Inpainting Model存在如下问题:
- Text misalignment:由于训练过程中的text prompt是针对全局图片的,所以模型会将mask region中填补背景内容,而不是根据针对mask region的text prompt进行精细的修复(e.g. Glide、Stable Inpainting,会把火烈鸟生成在背景部分)。
- Mask misalignment:结合多模态language-vision模型会捕捉全局信息,不会在给定的mask形状内生成内容(Blended diffusion)。
- Background preservation:会不经意修改inpainting object周围的背景区域(e.g. bottom row)。
贡献:
- 对于mask的精度进行控制,设定一个precision factor超参数,使模型对于不同精度的mask敏感。
- 训练时使用实例分割mask以及对应的局部文本描述。
- 进行实例mask预测,并作为正则化损失,使模型只在实例mask区域内生成内容。
- 多任务训练,联合训练inpainting任务和text-to-image generation,在pretrained模型上微调,以利用更多训练数据。
Method
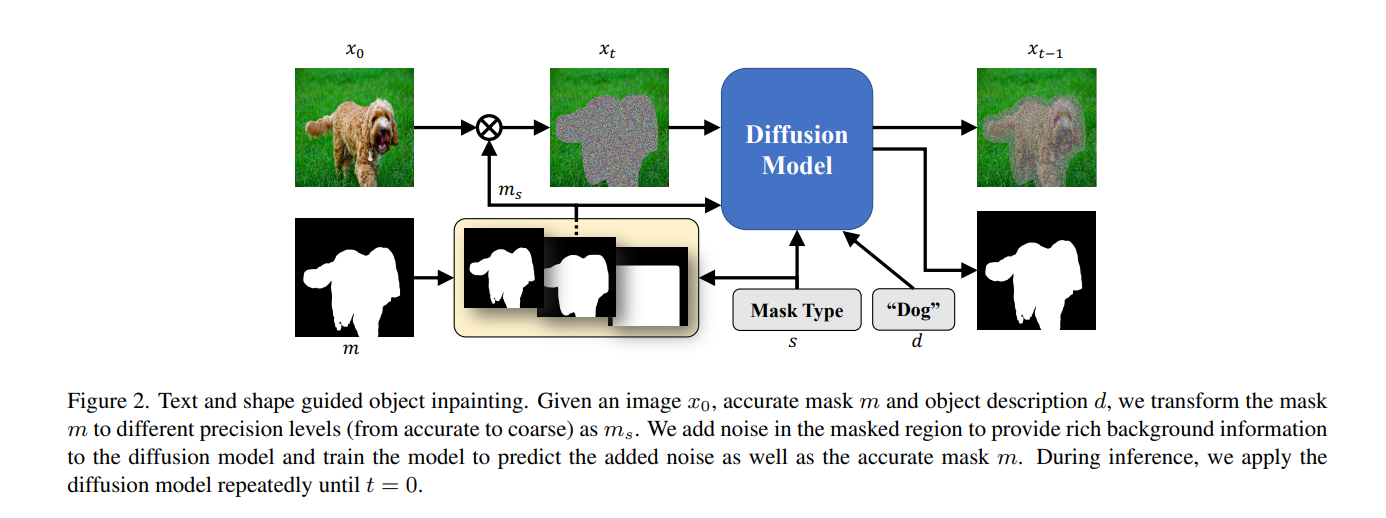
在原有的diffusion模型的基础上
- 只对mask区域加噪,学习上下文信息
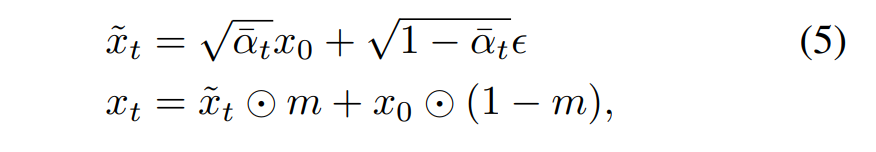
- 针对不同精度的mask,加入不同的条件控制,其中s是mask精度,m_s是实例分割对应的mask,c是实例的text label。
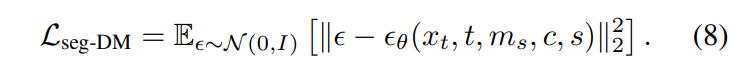
- 不论是什么样精度的mask,都要预测最精细的实例mask。
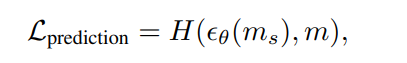
在已有的text-to-image生成模型(stable diffusion、Imagen)的预训练模型上微调,训练过程中将text-to-image的input mask设置为整张图片大小,作为inpainting的一个特殊情况。在8卡A100上训练了20K steps。
Evaluation
- 个人认为这种限定实例分割mask区域内修复的物体的效果,不如全局上直接生成效果好(更能fit in进原图,并且再画风上能保持一致性,因为是全局嵌入)
- 就像后期的一些diffusion-based+prompt2prompt方法进行图像编辑一样,或许人类指令(文本)会比精细mask的效果更好(实际上都是粗mask应用)、且交互性更强。
- 人类指令+粗mask或许是个值得follow的idea。

Paper | SmartBrush, Text and Shape Guided Object Inpainting with Diffusion Model | CVPR2023