Paper | Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning | AAAI2023
Info
Title:
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive LearningKeyword:Contrastive Learning、Segmentation Confusion Adversarial Training
Idea:Using Semantaion network predicts mask to distinguish generated and valid region,optimizing in an adversarial-style(between inpainting generator and a segmentation network)
Source
- Paper,2023年3月23号arXiv submitted,AAAI2023 Oral。Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning (arxiv.org)
- Code,未开源。
Abstract
- 【提出了一个针对Image Inpainting任务的对抗训练framework】(很勉强的说法),利用所提出的segmentation confusion adversarial training (SCAT) and contrastive learning。
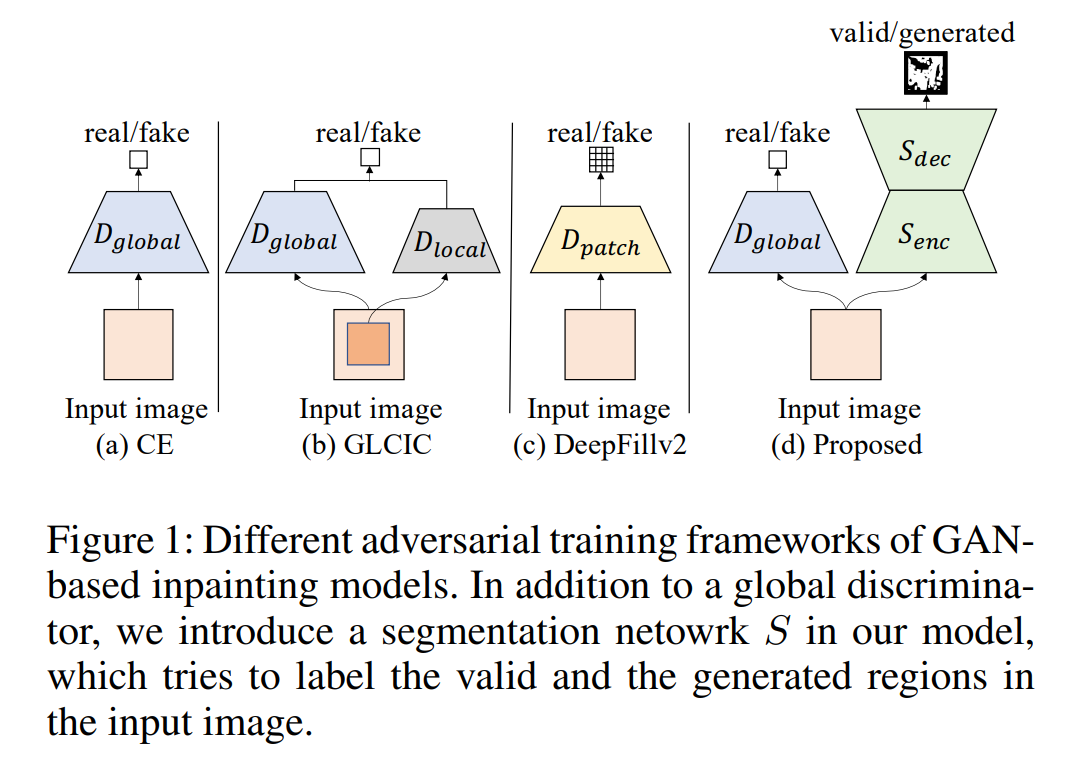
结合SCAT和全局对抗训练,有以下三个优势。
- repaired image的全局一致性
- 提升repaired image的局部精细纹理细节
- 处理不同图片free-form holes灵活性
这是现存的对抗训练框架难以同时满足的(但这对比的“现存”方法也都太考古了)。
Method
Motivation是人类能够轻易的寻找出扭曲或者纹理不一致的区域。本文利用分割网络来模拟这种人类行为,标记输入图像中的generated region和valid region,本质上是一个二分类语义分割。修复网络来“欺骗”分割网络,生成视觉语义上更合理填充内容,使得分割网络难以区分标记生成的部分(generated region)和原始的像素(valid region)。
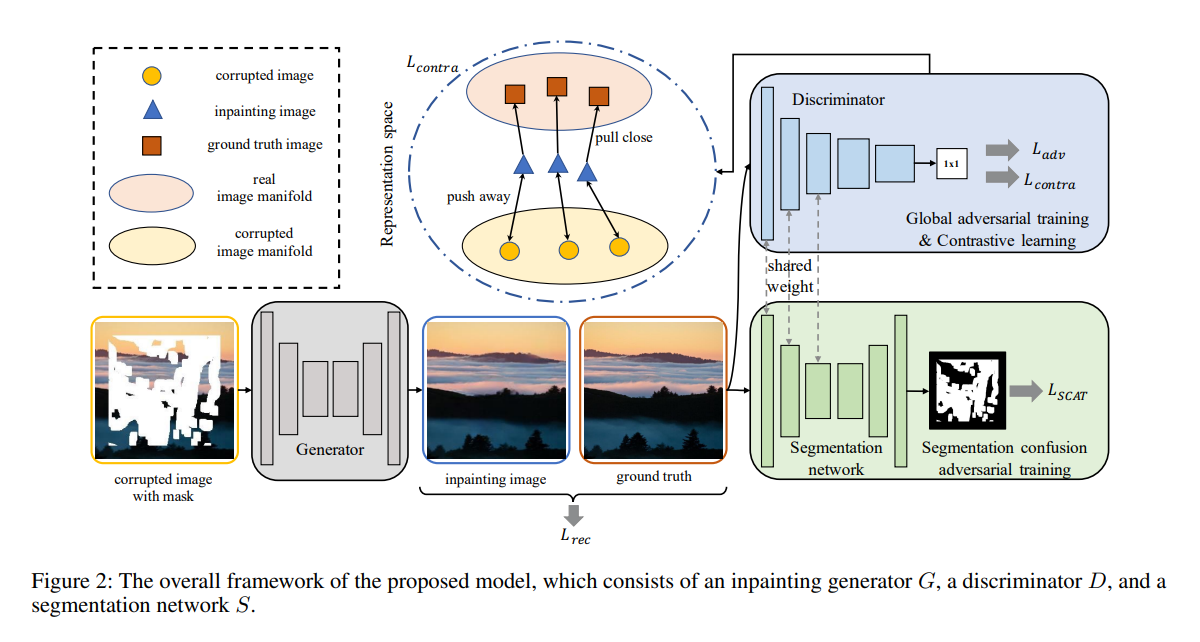
- 其中为m为输入mask,m-bar是全1mask代表真实图片的mask,repaired image为x-bar,gt image为x。对于inpainting generator G而言,利用m-bar来作为repaired image x-bar的监督,使得生成器能够生成更好的修复图像,以混淆分割网络S。S部分就是m作为repaired image的监督,m-bar作为gt的,使得S作为鉴别器学习不同图片内容中generated和valid像素分布。
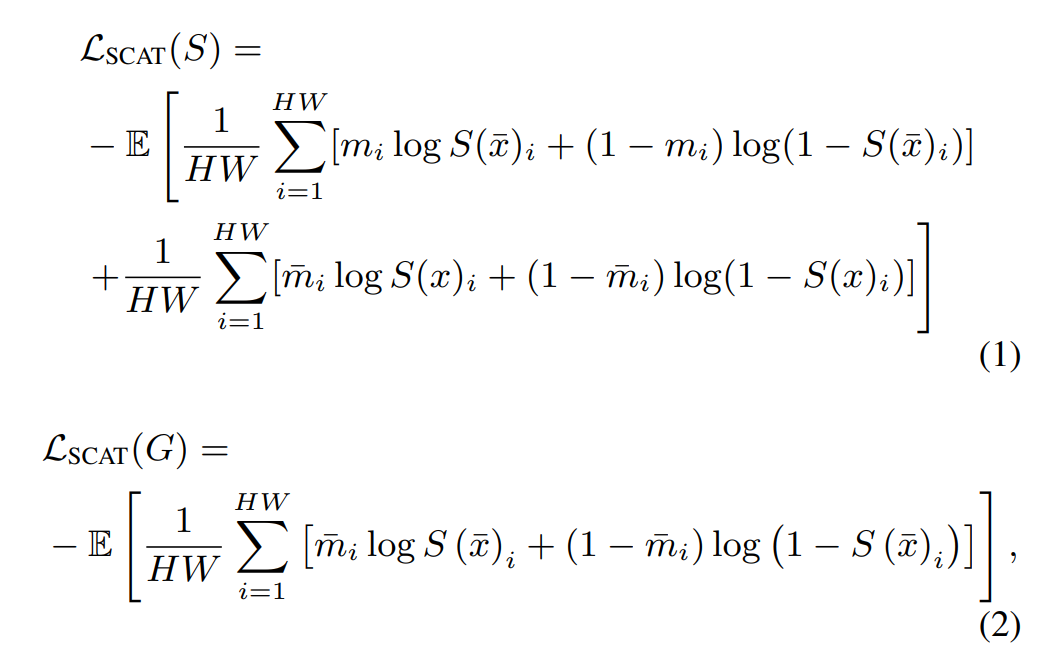
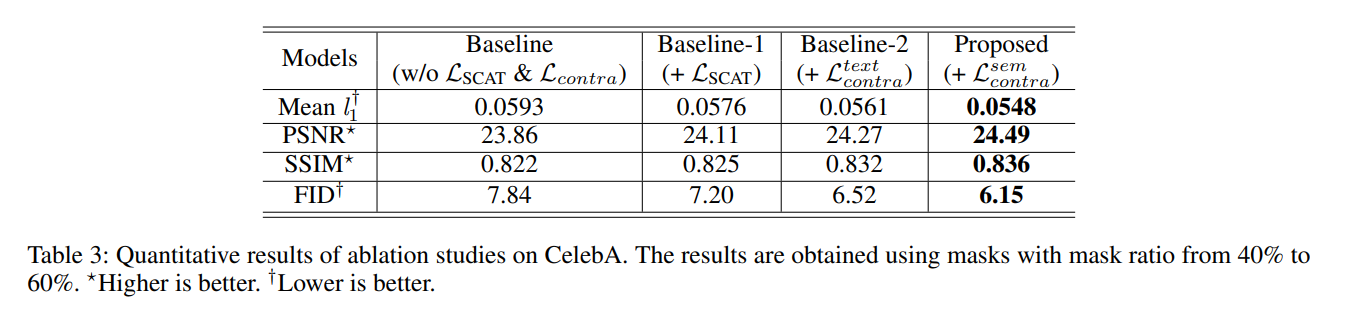
为了稳定GAN训练,加入对比学习损失,通过利用鉴别器的特征表示空间,在这个空间中将generated image分布拉向ground truth分布,同时远离corrupted image的分布。【作者说这是第一次将对比学习融入图像修复,说的很勉强】
- x-tilde为受损图片(就是mask和gt点乘得到的),鉴别器low-level特征为局部纹理细节,high-level为全局语义信息。取low-levelN个特征层计算纹理对比损失,接近gt分布而远离x-tilde(受损图像)分布;取鉴别器最后一个输出特征层计算语义对比损失,并构建多个x-tilde作为不同受损版本图片(超参数取8)。
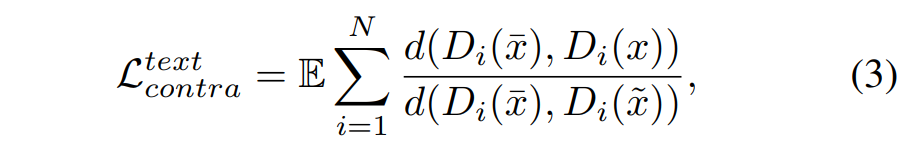
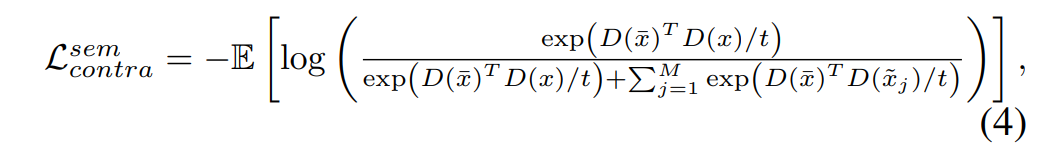
Evaluation
- 对比的新方法WaveFill、LaMa都是基于频率的,CTSDG是基于边缘先验的,在纹理复杂情况下效果都会差。

- 在CelebA数据集上的人脸修复定性比烂结果。

- 不过在irregular mask+CelebA数据集上的定性数据挺好看的,但没做过这个数据集以及places2数据集上的实验,不能确定这个效果是否性能很好。
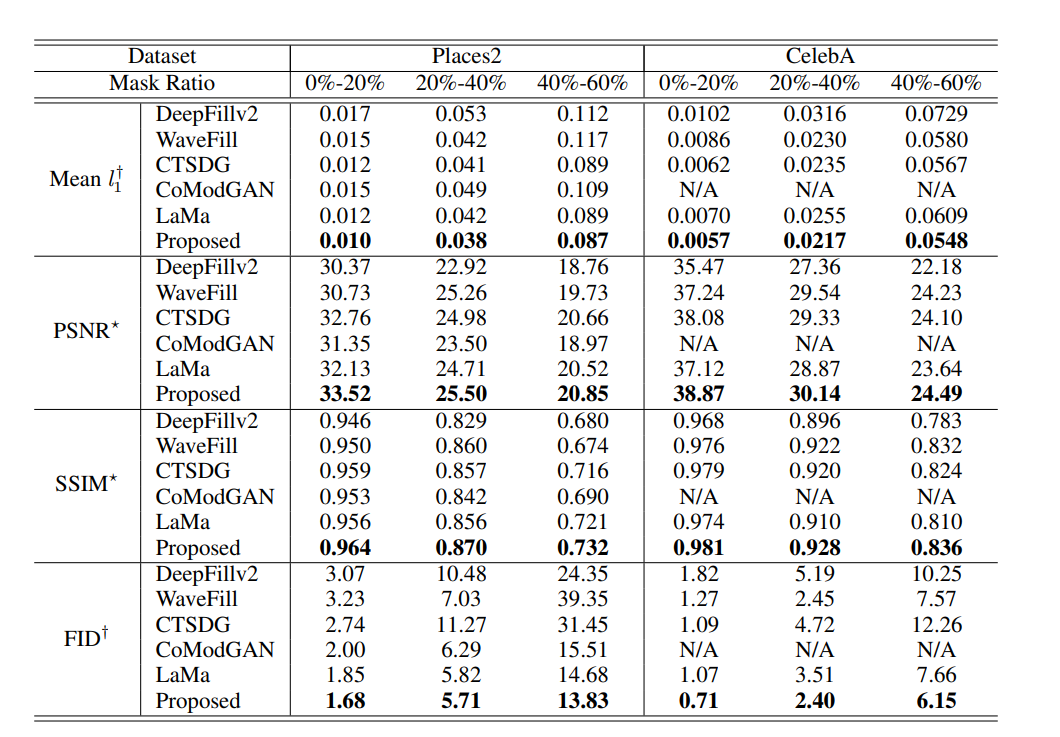
- 并且在40%-60%缺失区域的人脸修复中效果也还不错。

Paper | Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning | AAAI2023