Paper | Visual ChatGPT Talking, Drawing and Editing with Visual Foundation Models | arXiv2023
Info
- Title:
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models - Keyword:Large Language Model(LLM),Visual Foundation Model(VFM)
- Idea:Prompt Engineering
- Source
- Paper,2023年3月8日ArXiv Submitted,微软亚洲研究院的一项新工作。2303.04671] Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models (arxiv.org)
- Code,刚发布几天,目前已经有1万多标星了。microsoft/visual-chatgpt: VisualChatGPT (github.com)
Abstract
存在的问题:
大型语言模型如ChatGPT利用单一语言模态训练,因此处理视觉信息的能力非常有限。
相比较而言,视觉基础模型(VFM,Visual Foundation Models)在计算机视觉方面潜力巨大,因而能够理解和生成复杂的图像(如ViT、BLIP、Stable Diffusion等等)。VFM模型对输入-输出格式的苛求和固定限制,使得其在人机交互方面不如会话语言模型灵活。
贡献:
- Prompt Engineering:将ChatGPT和多个SOTA视觉基础模型连接。
Method
没有任何的训练,系统构成:
Part 1 ChatGPT(直接利用大语言集成工具LangChain,调用OpenAI text-davinci-003 version)
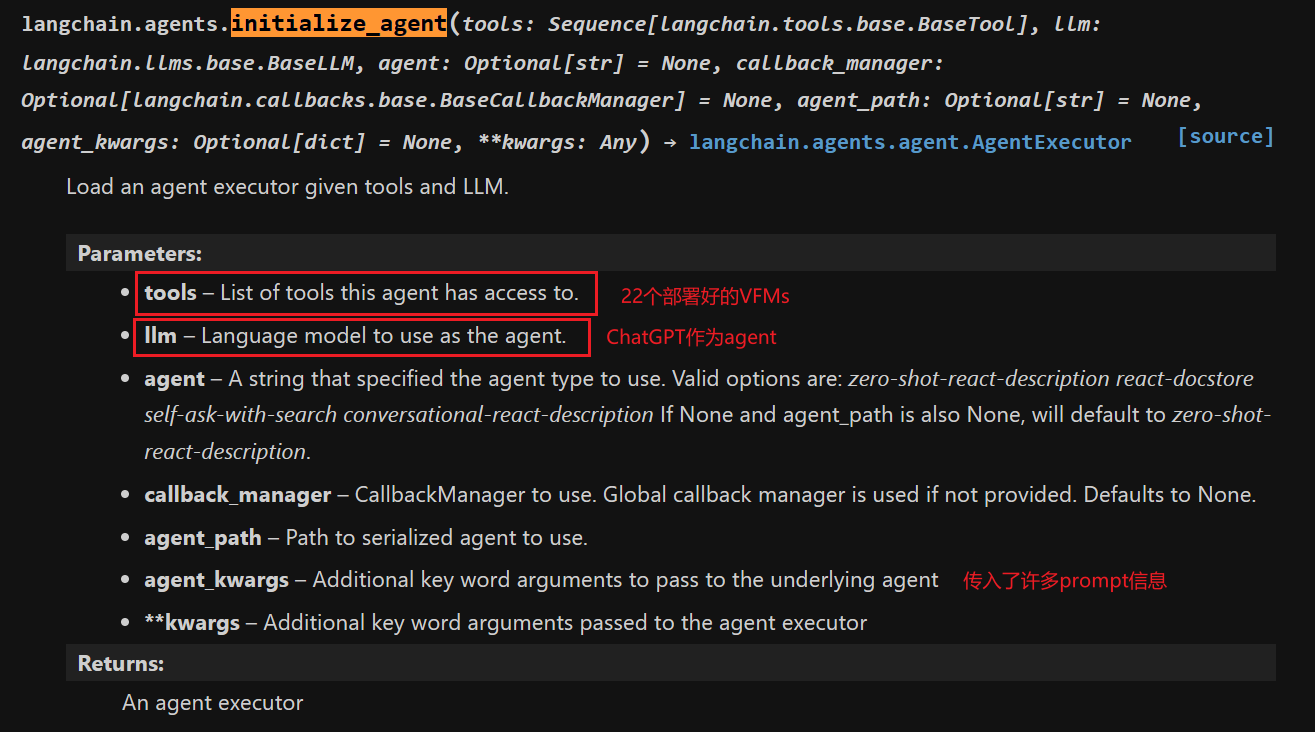
Part 2 PromptManager
构造了一个巨大的Prompt,把系统规则、视觉基础模型调用、历史对话、用户query、历史推理、中间结果都包含,简单来说就是指导ChatGPT怎么调用模型,什么时候调用,怎么处理结果。ChatGPT和VFMs之间沟通提到图片的时候使用的是随机生成的uuid(universally unique identifier),两者之间是没有向量或者图片数据交互的。
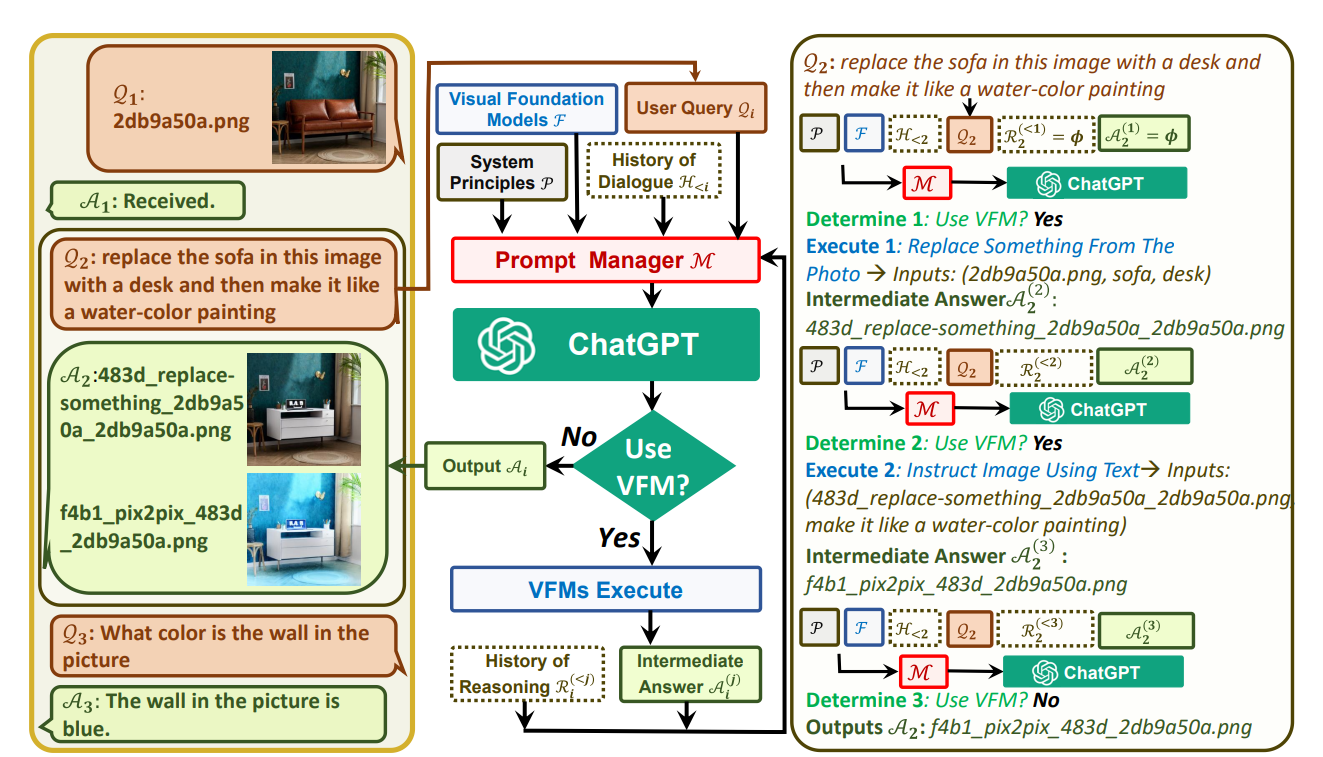
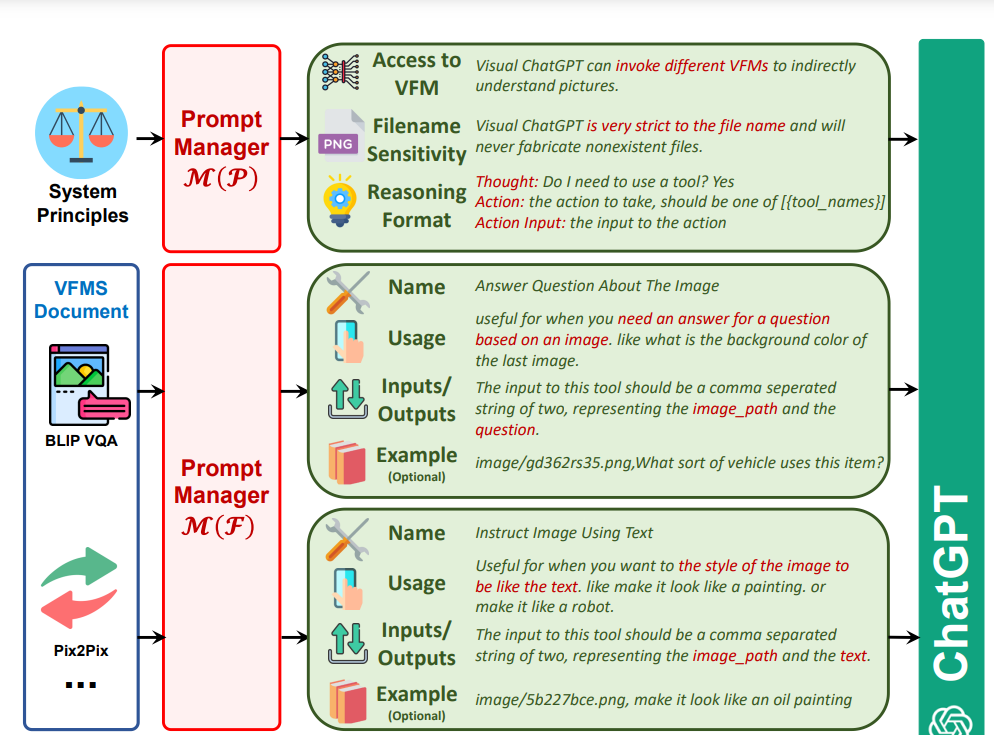
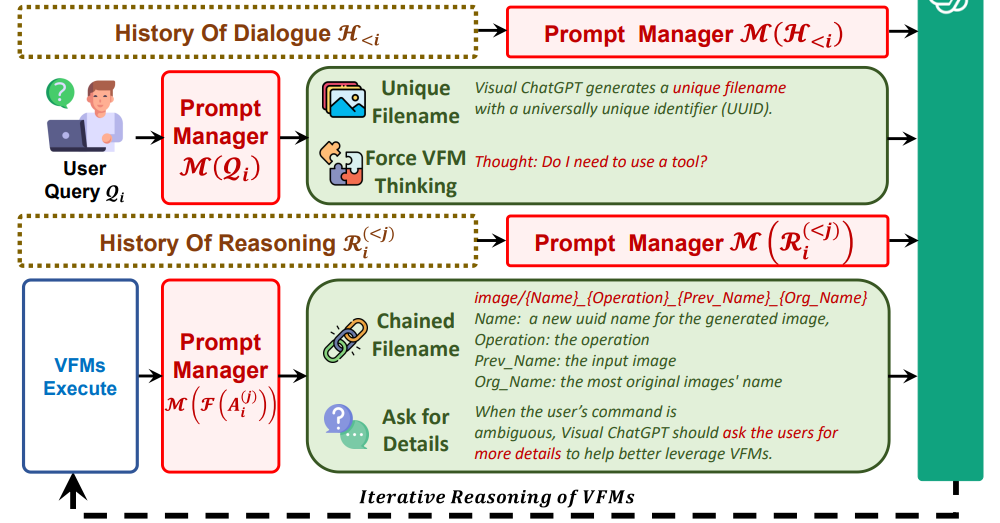
Part 3 VFMs(22个训练好的SOTA视觉基础模型,直接调用,利用4张V100就能全部部署)

Result
- 不是真正的多模态大模型,不过是普通玩家(小公司)可以尝试的Prompt Engineering。
- 训练一个多任务的large-scale视觉-语言模型应该非常消耗算力吧,23年3月15日发布的gpt4虽然没有公开详细的技术细节,但我觉得底层加了Vision QA,也就是Image-to-Text的能力,还是很难将I2I,T2I,I2T完全结合再一起的。
- 不过大力出奇迹,stack more layers,feed more data。
- 猜测GPT4背后的一些图像能力是靠这样的简单逻辑实现的。


References
Paper | Visual ChatGPT Talking, Drawing and Editing with Visual Foundation Models | arXiv2023