Paper | Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding | CVPR2022
Info
- Title:
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding - Keyword:Transformer, High resolution Image Inpainting
- Idea:Extract edges and contours with Transformer, Masking Positional Encoding
- Source
- Paper,2022年3月submitted的,到现在已经一年过去了,accepted in CVPR2022。[2203.00867] Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (arxiv.org)
- Code,基于LaMa做的一些小改进。DQiaole/ZITS_inpainting: Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (CVPR2022) (github.com),Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (dqiaole.github.io)
- PaperReading,CVPR2022|基于Transformer结构增强的增量式图像修复|ZITS - 知乎 (zhihu.com)非常好的阅读笔记。
Abstract v1
本文是基于WACV’22的高分辨率图像修复工作LaMa进一步改进的,更偏向于自然场景的修复(更注重结构、轮廓的先验信息)。
现存的问题:
1)现有的方法受限于CNN有限的感受野,只能处理常规的纹理,仍存在恢复生动纹理与合理的整体结构的问题(Vivid textures and Reasonable structures)。
2)Attention-based模型(Transformer)虽然能更好的学习长距离依赖(Long-range dependency),但是受限于高分辨率图像推理时的Heavy Computation。
解决的方法(贡献):
- 1)【主要贡献】An additional structure restorer,增加一个额外的结构修复器,增量式的辅助图像修复。
- 在固定的低分辨率Sketch space(Gray-scale space)修复整体的结构,并可以通过上采样融入到修复过程中。
- Can be integrated with other pretrained inpainting models efficiently with the zero-initialized residual addition(无需额外训练,直接融入到其他Inpainting预训练模型中)。
- 2)Masking positional encoding strategy用于提升使用Large irregular mask训练的性能。
Abstract v2
现存的问题:
- 现有的Inpainting方法只能处理regular textures,由于CNN感受野有限的问题,失去了对于图像整体结构(Holistic Structure)的把控。
- 基于attention的方法可以一定程度上解决该问题,但受限于高分辨率图像推理时的Heavy Computation。
贡献:
- Motivation:对于高分辨率自然图像修复来说,边缘信息十分重要,如果没有对于大图像的整体理解,很难恢复场景的边缘和线条,尤其是纹理较弱的场景。Method:使用一个额外的结构恢复网络,增量式的辅助图像修复过程。具体而言:transformer-based网络,在固定的低分辨率草图空间中,修复图像的边缘和轮廓线条,而后上采样到高分辨率,融合到后续图像修复网络中。
- Zero-initialized Residual Addition(零初始化残差融合)增量训练策略:提出的方法可以和其他的pretrained inpainting model轻易的整合在一起(许多其他利用先验信息的方法通常是多阶段多模型,训练成本高,而这个策略可以在较少的step数中快速收敛)。
- 提出了一个Masking Positional Encoding Strategy,提升在大mask配置下的模型性能。(高分辨率、较大缺失区域的修复,模型前期会在mask区域重复产生没有语义的伪影,浪费计算量)
Introduction
- Image Inpainting Goal:The inpainted images should remain both semantically coherent textures and visually reasonable structures. 这里也给了我们一点点启发,对于人脸修复而言,语义一致性至关重要,所以利用语义分割信息来引导人脸修复是一个好的想法;而后者,整体结构的连贯性,则对于自然场景图像修复至关重要。
- Image Inpainting任务现存的问题
- 1)Limited receptive fields。面对large corrupted region和高分辨率图像时问题更加凸显。
- 2)Missing holistic structures。缺乏整体结构,Recovering key edges and lines for scenes。
- 3) Heavy computations。训练高分辨率图像的GAN非常tricky and costly。
- 4) No positional information in masked regions。在大mask配置下,模型会生成没有意义伪影,浪费计算量。
很好,我的另一个Idea别人也已经实现了,好好看好好学吧(●’◡’●)
- 作者分析了LaMa的不足之处(其实非常明显),LaMa的本质是在频域内做了1×1卷积保证了相同周期性信号的关联,也就是LaMa作者想要解决的重复性纹理的修复。但是这样的方法无法确保整体结构,并且在纹理较弱的图像上性能很差。
最先使用transformer-based做low-resolution图像修复,然后再CNN上采样超分一下的工作。
Ziyu Wan, Jingbo Zhang, Dongdong Chen, and Jing Liao. High-fidelity pluralistic image completion with transformers. arXiv preprint arXiv:2103.14031, 2021.
Yingchen Yu, Fangneng Zhan, Rongliang Wu, Jianxiong Pan, Kaiwen Cui, Shijian Lu, Feiying Ma, Xuansong Xie, and Chunyan Miao. Diverse image inpainting with bidirectional and autoregressive transformers. arXiv preprint arXiv:2104.12335, 2021.
还有许多使用先验信息的网络,但通常都是多阶段图像修复,训练成本较高(trained from scratch)。
Method
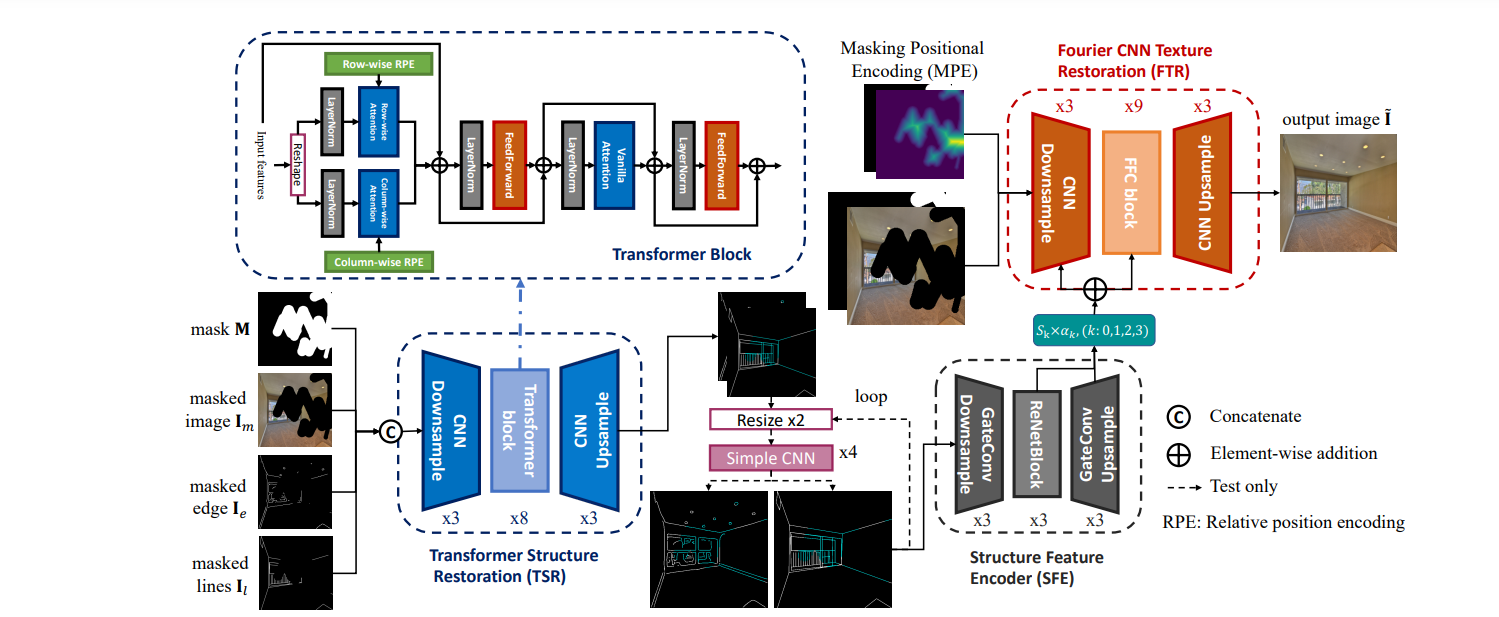
- 首先将mask、masked image(valid pixel为1,待填充区域为0,mask可视化时反转一下,待填充变为1,都是为了方便后续计算)、canny边缘提取器获得的masked edge(边缘)以及利用作者之前提出的模型获取的masked lines(线框,主要是建模两点之间的连线,所以上采样下采样时不存在歧义,但是canny边缘提取出来的信息在不同feature size提取出的边缘可能不同)。
- 送入TSR,首先将256×256的图片下采样三次到32×32大小,然后利用基于轴向注意力和常规注意力的transformer,减少计算量提升计算效率,最后获得256×256的修复后的边缘和线框。后续利用一个简单的四层CNN网络来对于修复好的先验信息进行上采样,只用线框数据进行训练而不用线框加边缘数据,这样做能够更好的消除歧义,获得不同分辨率更加一致的先验信息。
- 因为边缘和线框信息是稀疏的,所以利用基于门控卷积的网络来提取更关键的信息,并采用多尺度信息,也就是中间block的最后一层和上采样的三层,通过零初始化残差融合(就是做了一个简单的残差运算),和baseline LaMa的前四层融合在一起,然后训练50k进行一个增量学习微调就能显著的提升原模型的效果。
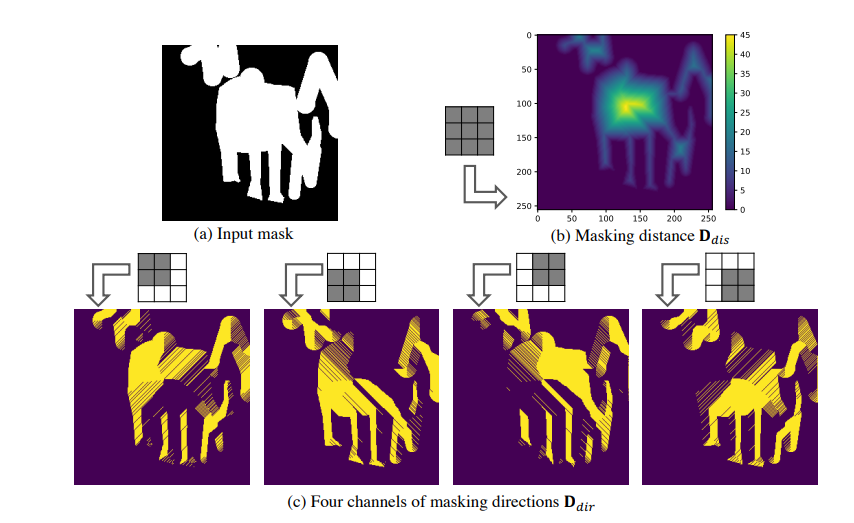
- 至于MPE(Masking Positional Encoding),其实就是取一个3×3的all-one卷积核来和mask区域做计算,能够获得距离大mask中心的距离信息以及mask方向信息,送入到baseline网络中作为辅助信息。(黑色区域为1白色为0,很简单的卷积运算)。
Evaluation
- 主要针对自然场景图像修复,定性上的性能增益不是很明显。
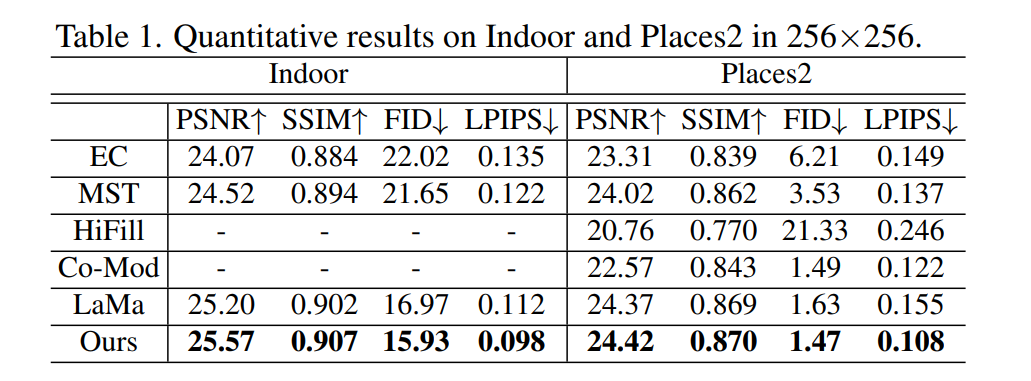
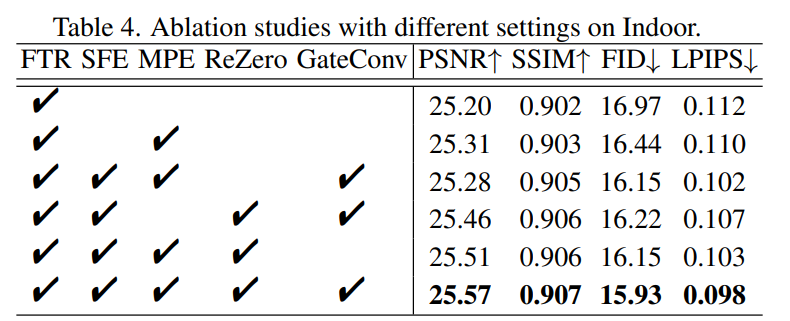
- MPE这个方法更是鸡肋,出发点很好但是做的太简单了,所以也没有多高的性能增益。
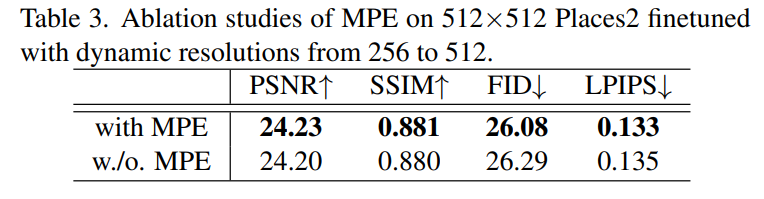
- 但是定性效果很好,主要是整体结构信息(边缘和线框)对于高分辨率的自然场景图像来说是非常关键的信息。作者之前提出的提取线框的模型,我觉得底层逻辑就像是透视图,对于空间布局来说,透视图很重要,所以修复出来的图片效果会更好。

Paper | Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding | CVPR2022