Paper | SFI-Swin Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions | arXiv2023
Info
Title:
SFI-Swin: Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components DistributionsKeyword:Face Inpainting、Swin Transformer
Idea:Symmetric(对称的,人脸对称性)、Distinctly Learning Face Components Distributions(显式学习面部组件分布)
Source
- Paper,2023年1月9号Submitted到arxiv上的。[2301.03130] SFI-Swin: Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions (arxiv.org)
- Code,Repo给出了但是代码还没有push上来。mohammadrezanaderi4/SFI-Swin: SFI-Swin: Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions https://arxiv.org/abs/2301.03130 (github.com)
日常感叹,为什么我能想到的Idea别人总能如此之快的抢发。当我还在拖拖拉拉实现Idea,别人已经验证完了。要多读paper,更重要的是多写code,实现Idea并验证哇。世界上最遥远的距离就是知道和做到。
Abstract
现存的问题(问题陈述):
None of the existing inpainting methods consider the symmetry and homogeneity of the picture.
现有的方法在人脸修复的过程中没有考虑图像的对称性和同质性。
The metrics that assess a repaired face image quality cannot measure the preservation of symmetry between the rebuilt and existing parts of a face.
现有的评估指标无法衡量修复人脸的对称性。
提出的方法(贡献点):
- 利用多discriminators分别验证五官的生成质量(提升对人脸高级语义五官的理解),构建一个transformer-based的网络(大感受野能够保证面部对称性)。
- 提出symmetry concentration score指标,来评估修复人脸的对称性。
- 在reality, symmetry, and homogeneity三个维度上,比最近提出的sota算法效果好。
Introduction
- 在图像处理中,同质性指的是测量图像的局部均匀性。
- 文章中的同质性指的是修复的缺失区域需要和面部的其他区域保持协调(global features of each part of the face)。The inpainted regions must be homogeneous with the other parts of the face and highly correlated to the available surrounding areas of the input image.
- 对称性指的是面部的左右对称。facial symmetry must be preserved between the left and right sides.
作者认为现存方法的问题出在了损失函数无法向生成器传达面部特征的整体理解。This shortcoming is because the network losses do not convey a general understanding of the facial features to the generator.
于是作者分析了主流Inpainting方法常用的几种loss对于模型训练的影响,包括pixel-wise, adversarial, feature-matching, and perceptual loss。
- pixel-wise loss。L1、L2范数,只能让网络理解到底层特征(low-level features)。👉focus on 底层特征(颜色、纹理)
- adversarial loss。能够让gt和生成图像的分布(distribution)接近,使用discriminator和generator构成博弈;feature-matching loss。gt和pred作为输入,提取discriminator中间层特征。这两个loss只能让生成的图片看起来真实,但不能保证missing regions exactly similar to ground truth(inpainting任务的不适定性,ill-posed problem),大多数鉴别器是patch-based的,所以只能保证局部真实感。👉focus on 生成patches内容的真实感
- perceptual loss。先利用一个seg network的预训练提取高级语义特征,然后计算L1、L2范数。主要考虑了high-level features,比如边缘。👉focus on 边缘轮廓的平滑性
一般是过一个类似VGG的backbone预训练提取特征,high-level features就默认为语义及以上层次的特征。
有时上述的loss会牺牲面部对称性而达到局部真实感的最优,所以我们现在需要💡homogeneity-aware loss均匀感知损失,来约束模型。同时,transformer的大感受野也能保证面部对称性。
Method
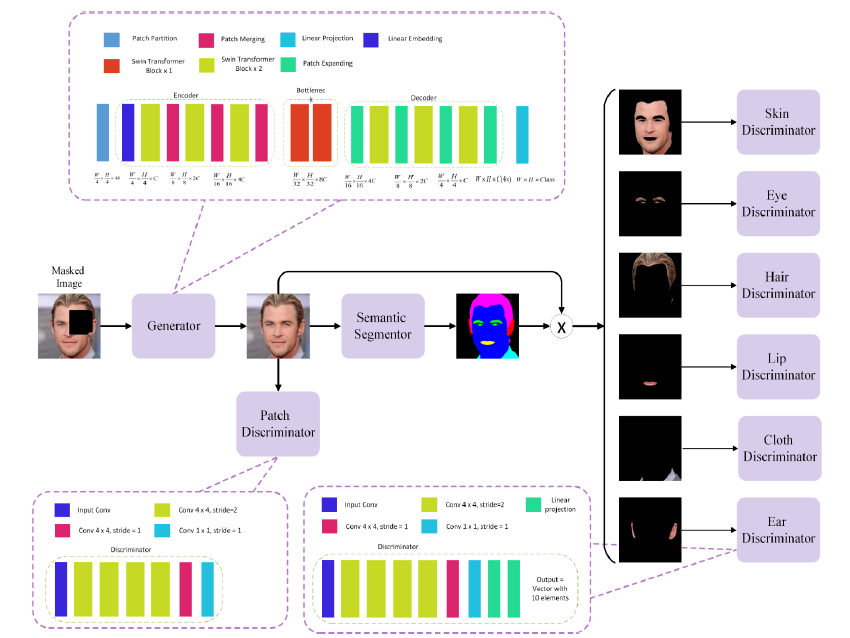

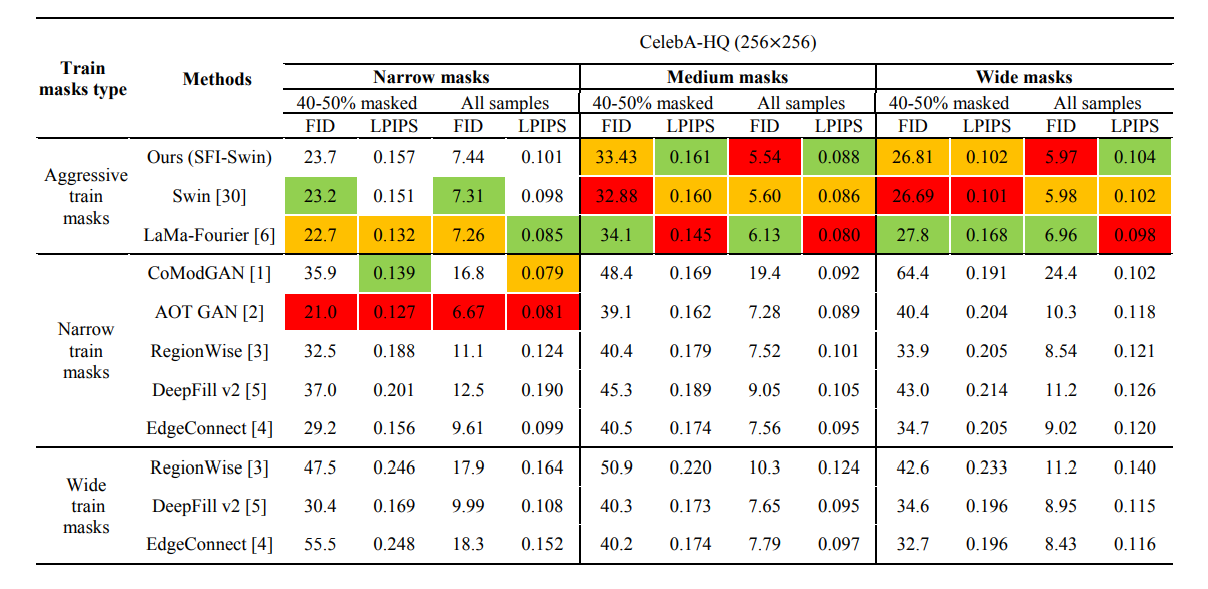
Evaluation
- 方法效果一般,更多的是Swin transformer带来的加成。
Paper | SFI-Swin Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions | arXiv2023